-
1. Começando
- 1.1 Sobre Controle de Versão
- 1.2 Uma Breve História do Git
- 1.3 O Básico do Git
- 1.4 A Linha de Comando
- 1.5 Instalando o Git
- 1.6 Configuração Inicial do Git
- 1.7 Pedindo Ajuda
- 1.8 Sumário
-
2. Fundamentos de Git
-
3. Branches no Git
-
4. Git no servidor
- 4.1 Os Protocolos
- 4.2 Getting Git on a Server
- 4.3 Gerando Sua Chave Pública SSH
- 4.4 Setting Up the Server
- 4.5 Git Daemon
- 4.6 Smart HTTP
- 4.7 GitWeb
- 4.8 GitLab
- 4.9 Third Party Hosted Options
- 4.10 Sumário
-
5. Distributed Git
-
6. GitHub
- 6.1 Configurando uma conta
- 6.2 Contribuindo em um projeto
- 6.3 Maintaining a Project
- 6.4 Managing an organization
- 6.5 Scripting GitHub
- 6.6 Summary
-
7. Git Tools
- 7.1 Revision Selection
- 7.2 Interactive Staging
- 7.3 Stashing and Cleaning
- 7.4 Signing Your Work
- 7.5 Searching
- 7.6 Rewriting History
- 7.7 Reset Demystified
- 7.8 Advanced Merging
- 7.9 Rerere
- 7.10 Debugging with Git
- 7.11 Submodules
- 7.12 Bundling
- 7.13 Replace
- 7.14 Credential Storage
- 7.15 Summary
-
8. Customizing Git
- 8.1 Git Configuration
- 8.2 Git Attributes
- 8.3 Git Hooks
- 8.4 An Example Git-Enforced Policy
- 8.5 Summary
-
9. Git and Other Systems
- 9.1 Git as a Client
- 9.2 Migrating to Git
- 9.3 Summary
-
10. Funcionamento Interno do Git
- 10.1 Encanamento e Porcelana
- 10.2 Objetos do Git
- 10.3 Referências do Git
- 10.4 Packfiles
- 10.5 The Refspec
- 10.6 Transfer Protocols
- 10.7 Maintenance and Data Recovery
- 10.8 Variáveis de ambiente
- 10.9 Sumário
-
A1. Appendix A: Git em Outros Ambientes
- A1.1 Graphical Interfaces
- A1.2 Git in Visual Studio
- A1.3 Git in Eclipse
- A1.4 Git in Bash
- A1.5 Git in Zsh
- A1.6 Git in Powershell
- A1.7 Resumo
-
A2. Appendix B: Embedding Git in your Applications
- A2.1 Command-line Git
- A2.2 Libgit2
- A2.3 JGit
-
A3. Appendix C: Git Commands
- A3.1 Setup and Config
- A3.2 Getting and Creating Projects
- A3.3 Basic Snapshotting
- A3.4 Branching and Merging
- A3.5 Sharing and Updating Projects
- A3.6 Inspection and Comparison
- A3.7 Debugging
- A3.8 Patching
- A3.9 Email
- A3.10 External Systems
- A3.11 Administration
- A3.12 Plumbing Commands
10.2 Funcionamento Interno do Git - Objetos do Git
Objetos do Git
O Git é um sistema de arquivos de conteúdo endereçável.
Ótimo.
O que isso significa?
Isso significa que o coração do Git é um simples armazenamento chave-valor.
Você pode inserir qualquer tipo de conteúdo nele, e ele lhe dará de volta uma chave que você pode usar para recuperar o conteúdo de volta em qualquer momento.
Para demonstrar isso, você pode usar o comando de encanamento hash-object, que recebe alguns dados, armazena eles em seu diretório .git, e lhe devolve de volta a chave com o qual os dados são armazenados.
Primeiramente, inicialize um novo repositório Git e verifique que não há nada no diretório objects:
$ git init test
Initialized empty Git repository in /tmp/test/.git/
$ cd test
$ find .git/objects
.git/objects
.git/objects/info
.git/objects/pack
$ find .git/objects -type fO Git inicializou o diretório objects diretamente e criou os subdiretórios pack e info dentro dele, mas não há nenhum arquivo regular.
Agora, guarde algum texto no seu banco de dados do Git:
$ echo 'test content' | git hash-object -w --stdin
d670460b4b4aece5915caf5c68d12f560a9fe3e4A flag`-w` diz ao hash-object para armazenar o objeto. Caso contrário, o comando simplesmente lhe diria a chave.
--stdin diz ao comando para ler o conteúdo do stdin; se você não especificar isto, hash-object espera um caminho para um arquivo no fim.
A saída do comando é um checksum hash de 40 caracteres.
Esse é o hash SHA-1 - um checksum do conteúdo que você está armazendo mais um cabeçalho, que você aprenderá em breve.
Agora você pode ver como o Git armazenou seus dados:
$ find .git/objects -type f
.git/objects/d6/70460b4b4aece5915caf5c68d12f560a9fe3e4Você pode ver um arquivo no diretório objects.
É assim que o Git armazena o conteúdo inicialmente - como um simples arquivo por porção de conteúdo, nomeado com o checksum SHA-1 do conteúdo e seu cabeçalho.
O subdiretório é nomeado com os dois primeiros caracteres do SHA-1, e o nome do arquivo são os 38 caracteres restantes.
Você pode recuperar o conteúdo para fora do Git com o comando cat-file.
Esse comando é um canivete suíço para a inspeção de objetos do Git.
Passando -p para ele faz com que o cat-file descubra o tipo do conteúdo e o mostre gentilmente para você:
$ git cat-file -p d670460b4b4aece5915caf5c68d12f560a9fe3e4
test contentAgora, você pode adicionar conteúdo para o Git e recuperá-lo de volta. Você também pode fazer isso para conteúdos em arquivos. Por exemplo, você pode fazer um controle de versão simples em um arquivo. Primeiro, crie um arquivo e salve seus conteúdos em seu banco de dados:
$ echo 'version 1' > test.txt
$ git hash-object -w test.txt
83baae61804e65cc73a7201a7252750c76066a30Depois, escreva alguns conteúdos novos nesse arquivo, e salve-o novamente:
$ echo 'version 2' > test.txt
$ git hash-object -w test.txt
1f7a7a472abf3dd9643fd615f6da379c4acb3e3aSeu banco de dados contém as duas novas versões do arquivo, além do primeiro conteúdo que você gravou:
$ find .git/objects -type f
.git/objects/1f/7a7a472abf3dd9643fd615f6da379c4acb3e3a
.git/objects/83/baae61804e65cc73a7201a7252750c76066a30
.git/objects/d6/70460b4b4aece5915caf5c68d12f560a9fe3e4Agora você pode reverter o arquivo de volta à primeira versão:
$ git cat-file -p 83baae61804e65cc73a7201a7252750c76066a30 > test.txt
$ cat test.txt
version 1ou à segunda versão:
$ git cat-file -p 1f7a7a472abf3dd9643fd615f6da379c4acb3e3a > test.txt
$ cat test.txt
version 2Lembrando que decorar a chave SHA-1 para cada versão de seu arquivo não é prático; além disso, você não está armazenando o nome do arquivo em seu sitema - apenas o conteúdo.
Este tipo de objeto é chamado de blob.
Você pode pedir para o Git lhe dizer o tipo de objeto de qualquer objeto, dado sua chave SHA-1, com cat-file -t:
$ git cat-file -t 1f7a7a472abf3dd9643fd615f6da379c4acb3e3a
blobObjetos Tree
O próximo tipo que iremos ver é a tree (árvore), que resolve o problema de armazenar o nome de arquivo e também permite armazenar de forma conjunta um grupo de arquivos. O Git armazena o conteúdo em uma maneira similar a um sistema de arquivos UNIX, porém um pouco simplificado. Todo o conteúdo é armazenado como objetos tree e blob, com as trees correspondendo a entradas de um diretório UNIX e blobs correspondendo mais ou menos a inodes ou conteúdos de arquivos. Um único objeto tree contém uma ou mais entradas, cada uma contendo uma referência SHA-1 para um blob ou subtree com seu modo, tipo e nome de arquivo associados. Por exemplo, a tree mais recente em um projeto deverá se parecer com algo assim:
$ git cat-file -p master^{tree}
100644 blob a906cb2a4a904a152e80877d4088654daad0c859 README
100644 blob 8f94139338f9404f26296befa88755fc2598c289 Rakefile
040000 tree 99f1a6d12cb4b6f19c8655fca46c3ecf317074e0 libA sintaxe master^{tree} especifica o objeto tree que é apontado pelo último commit em sua branch master .
Note que o subdiretório lib não é um blob, mas uma referência para outra tree:
$ git cat-file -p 99f1a6d12cb4b6f19c8655fca46c3ecf317074e0
100644 blob 47c6340d6459e05787f644c2447d2595f5d3a54b simplegit.rbConceitualmente, os dados que são armazenados pelo Git é algo assim:
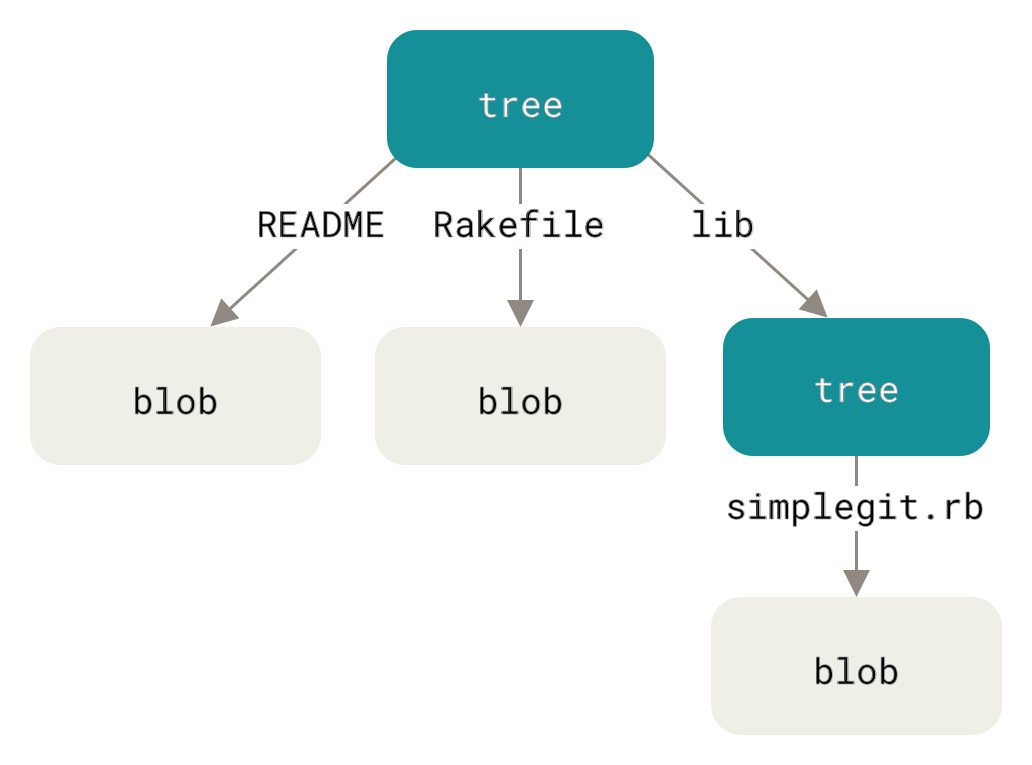
Você pode criar facilmente a sua própria tree.
O Git normalmente cria uma tree a partir do estado da sua área de stage ou index e escrevendo uma série de objetos tree a partir dela.
Então, para criar um objeto tree, você primeiro precisa popular um index adicionando alguns arquivos.
Para criar um index com apenas uma entrada - a primeira versão do do seu arquivo test.txt - você pode usar o comando update-index.
Você usa esse comando para adicionar artificialmente a versão anterior do arquivo test.txt à nova área de stage.
Você precisa passar a ele a opção --add porque o arquivo ainda não existe em sua área de stage (você nem precisa ter uma área de stage ainda) e a opção --cacheinfo porque o arquivo que você está adicionando não está em seu diretório mas está no seu banco de dados.
Depois você especifica o modo, o SHA-1 e o nome do arquivo:
$ git update-index --add --cacheinfo 100644 \
83baae61804e65cc73a7201a7252750c76066a30 test.txtNeste caso, você está especificando um modo 100644, o que significa se trata de um arquivo normal.
Outras opções são 100755, o que significa que é um arquivo executável; e 120000, que especifica um link simbólico.
O modo vem dos modos UNIX normais, mas é muito menos flexível - esses três modos são os únicos que são válidos para arquivos (blobs) no Git (ainda que outros modos possam ser usados para diretórios e submódulos).
Agora, você pode usar o comando write-tree para escrever a área de stage para um objeto tree.
A opção -w não é necessária - chamar write-tree automaticamente cria um objeto tree a partir do estado do index caso a tree ainda não exista:
$ git write-tree
d8329fc1cc938780ffdd9f94e0d364e0ea74f579
$ git cat-file -p d8329fc1cc938780ffdd9f94e0d364e0ea74f579
100644 blob 83baae61804e65cc73a7201a7252750c76066a30 test.txtVocê também pode verificar que se este é um arquivo tree:
$ git cat-file -t d8329fc1cc938780ffdd9f94e0d364e0ea74f579
treeVocê pode criar um novo arquivo tree com a segunda versão de test.txt, além de um novo arquivo:
$ echo 'new file' > new.txt
$ git update-index --cacheinfo 100644 \
1f7a7a472abf3dd9643fd615f6da379c4acb3e3a test.txt
$ git update-index test.txt
$ git update-index --add new.txtSua área de stage agora tem a nova versão de test.txt, bem como o novo arquivo new.txt.
Escreva essa tree (grave o estado da área de stage ou index para um objeto) e veja como ela se parece:
$ git write-tree
0155eb4229851634a0f03eb265b69f5a2d56f341
$ git cat-file -p 0155eb4229851634a0f03eb265b69f5a2d56f341
100644 blob fa49b077972391ad58037050f2a75f74e3671e92 new.txt
100644 blob 1f7a7a472abf3dd9643fd615f6da379c4acb3e3a test.txtNote que essa tree tem ambas as entradas de arquivo além de que o SHA-1 de test.txt é a o SHA-1 da “versão 2” que falamos anteriormente (1f7a7a).
Apenas por diversão, adicione a primeira tree como um subdiretório neste aqui.
Você pode ler as trees para a área de stage chamando read-tree.
Neste caso, você pode ler uma tree existente em sua área de stage como uma subtree usando a opção --prefix em read-tree:
$ git read-tree --prefix=bak d8329fc1cc938780ffdd9f94e0d364e0ea74f579
$ git write-tree
3c4e9cd789d88d8d89c1073707c3585e41b0e614
$ git cat-file -p 3c4e9cd789d88d8d89c1073707c3585e41b0e614
040000 tree d8329fc1cc938780ffdd9f94e0d364e0ea74f579 bak
100644 blob fa49b077972391ad58037050f2a75f74e3671e92 new.txt
100644 blob 1f7a7a472abf3dd9643fd615f6da379c4acb3e3a test.txtSe você criasse um diretório de trabalho a partir da nova tree que você criou, você teria os dois arquivos no nível mais alto do diretório de trabalho e um subdiretório chamado bak que conteria a primeira versão do arquivo test.txt.
Você pode pensar nos dados que o Git armazena para essas estruturas como sendo algo assim:
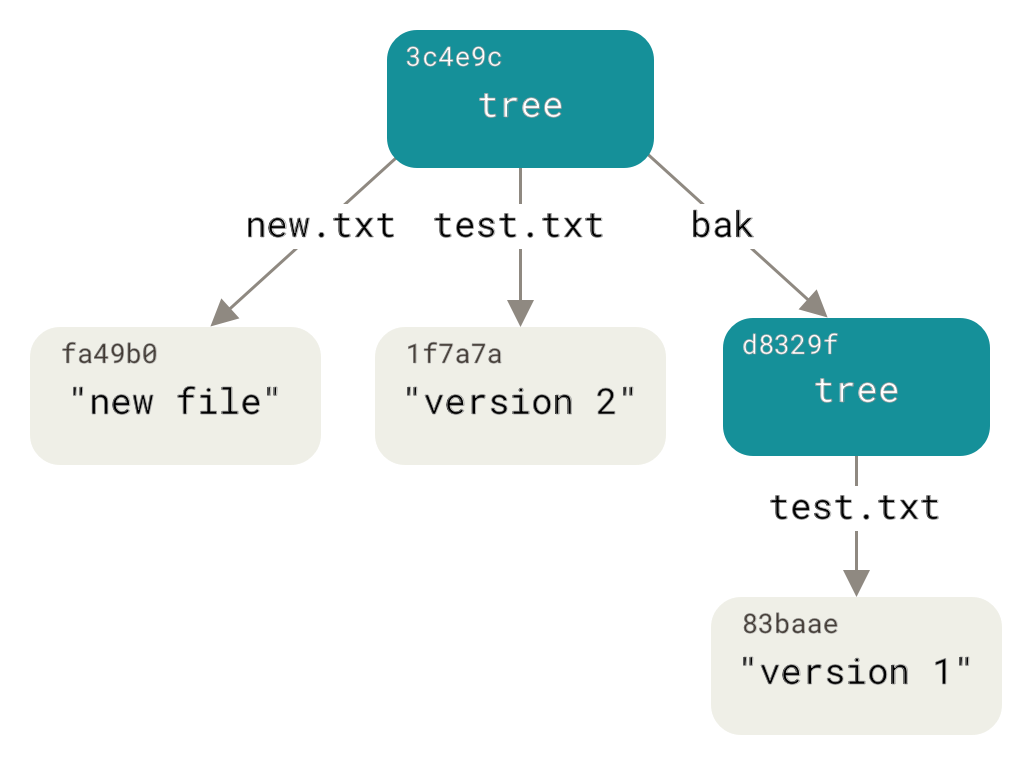
Objetos Commit
Agora você tem três trees que especificam os diferentes snapshots do seu projeto que você gostaria de rastrear, mas o problema anterior se mantém: você precisa lembrar dos três valores dos SHA-1 para encontrar os snapshots Você também não tem nenhuma informação sobre quem salvou os snapshots, quando eles foram salvos, ou porque eles foram salvos. Essas são informações básicas que o objeto commit armazena para você.
Para criar um objeto commit, você chama commit-tree e especifica o SHA-1 de uma única tree e quais objetos commit precedem diretamente ele, se houver.
Começando com a primeira tree que você escreveu:
$ echo 'first commit' | git commit-tree d8329f
fdf4fc3344e67ab068f836878b6c4951e3b15f3dVocê irá obter um valor diferente para o hash por causa das diferentes hora de criação e dados do autor.
Substitua os hashes de commit e tag pelos seus próprios checksums posteriormente neste capítulo.
Agora você pode olhar para o seu novo objeto commit com cat-file:
$ git cat-file -p fdf4fc3
tree d8329fc1cc938780ffdd9f94e0d364e0ea74f579
author Scott Chacon <schacon@gmail.com> 1243040974 -0700
committer Scott Chacon <schacon@gmail.com> 1243040974 -0700
first commitO formato para um objeto commit é simples: ele especifica a tree de nível mais alto para o snapshot do projeto neste ponto; a informação do autor/commiter (que usa as configurações user.name e user.email, além de um timestamp); uma linha em branco e então a mensagem de commit.
A seguir, você irá escrever outros dois objetos commit, cada um referenciando o commit que veio diretamente antes dele:
$ echo 'second commit' | git commit-tree 0155eb -p fdf4fc3
cac0cab538b970a37ea1e769cbbde608743bc96d
$ echo 'third commit' | git commit-tree 3c4e9c -p cac0cab
1a410efbd13591db07496601ebc7a059dd55cfe9Cada um dos três objetos commit aponta para uma das três trees de snapshot que você criou.
Curiosamente, você tem agora um histórico do Git real que você pode ver com o comando git log, se você executá-lo no SHA-1 do último commit:
$ git log --stat 1a410e
commit 1a410efbd13591db07496601ebc7a059dd55cfe9
Author: Scott Chacon <schacon@gmail.com>
Date: Fri May 22 18:15:24 2009 -0700
third commit
bak/test.txt | 1 +
1 file changed, 1 insertion(+)
commit cac0cab538b970a37ea1e769cbbde608743bc96d
Author: Scott Chacon <schacon@gmail.com>
Date: Fri May 22 18:14:29 2009 -0700
second commit
new.txt | 1 +
test.txt | 2 +-
2 files changed, 2 insertions(+), 1 deletion(-)
commit fdf4fc3344e67ab068f836878b6c4951e3b15f3d
Author: Scott Chacon <schacon@gmail.com>
Date: Fri May 22 18:09:34 2009 -0700
first commit
test.txt | 1 +
1 file changed, 1 insertion(+)Incrível.
Você acabou de fazer operações de baixo nível para criar um histórico do Git sem usar nenhum dos comandos de front-end.
Isso é essencialmente o que o Git faz quando você executa os comandos git add e git commit - ele armazena blobs para os arquivos que mudaram, atualiza o index, escreve as trees e escreve os objetos commit que referenciam as trees de mais alto nível e os commits que vieram imediatamente antes deles.
Esses três principais objetos do Git - o blob, a tree, e o commit - são inicialmente armazenados como arquivos separados em seu diretório .git/objects.
Estes são todos os objetos no diretório de exemplo, comentados com o que eles armazenam:
$ find .git/objects -type f
.git/objects/01/55eb4229851634a0f03eb265b69f5a2d56f341 # tree 2
.git/objects/1a/410efbd13591db07496601ebc7a059dd55cfe9 # commit 3
.git/objects/1f/7a7a472abf3dd9643fd615f6da379c4acb3e3a # test.txt v2
.git/objects/3c/4e9cd789d88d8d89c1073707c3585e41b0e614 # tree 3
.git/objects/83/baae61804e65cc73a7201a7252750c76066a30 # test.txt v1
.git/objects/ca/c0cab538b970a37ea1e769cbbde608743bc96d # commit 2
.git/objects/d6/70460b4b4aece5915caf5c68d12f560a9fe3e4 # 'test content'
.git/objects/d8/329fc1cc938780ffdd9f94e0d364e0ea74f579 # tree 1
.git/objects/fa/49b077972391ad58037050f2a75f74e3671e92 # new.txt
.git/objects/fd/f4fc3344e67ab068f836878b6c4951e3b15f3d # commit 1Se você seguir as referências internas, você obterá um grafo de objetos mais ou menos como este:
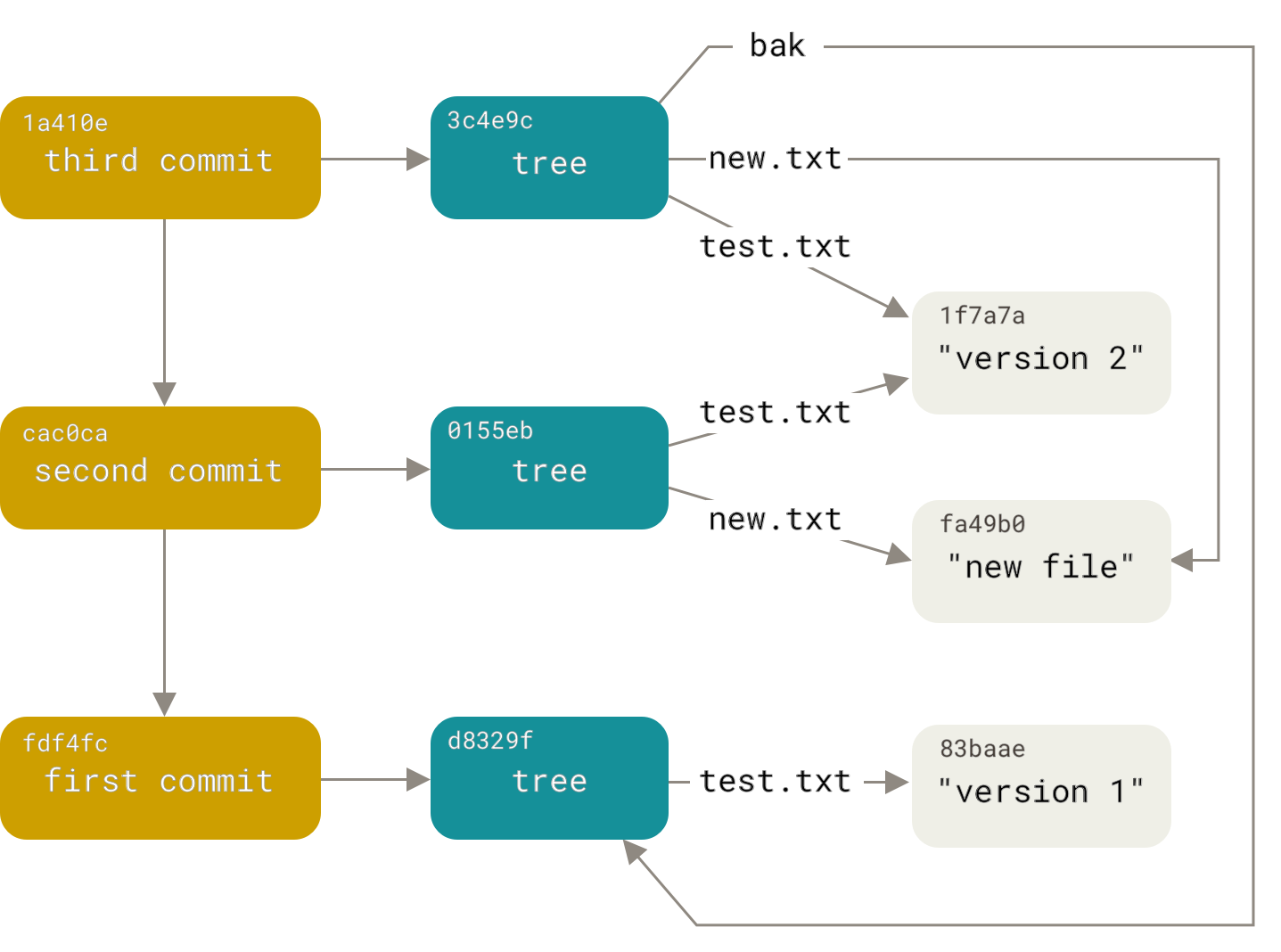
Armazenamento de Objetos
Mencionamos anteriormente que o cabeçalho é armazenado junto com o conteúdo. Vamos tomar um minuto para olhar como o Git armazena seus objetos. Você verá como armazenar um objeto blob - neste caso, a string “what is up, doc?” - interativamente usando a linguagem de script Ruby.
Você pode iniciar o modo interativo do Ruby com o comando irb:
$ irb
>> content = "what is up, doc?"
=> "what is up, doc?"O Git constrói um cabeçalho que começa com o tipo de objeto, neste caso, um blob. Depois, ele adiciona um espaço seguido do tamanho do conteúdo e finalmente um byte nulo:
>> header = "blob #{content.length}\0"
=> "blob 16\u0000"O Git concatena o cabeçalho e o conteúdo original e então calcula o checksum SHA-1 do novo conteúdo.
Você pode calcular o valor SHA-1 de uma string em Ruby incluindo a biblioteca SHA1 digest com o comando require e então chamando Digest::SHA1.hexdigest() com a string:
>> store = header + content
=> "blob 16\u0000what is up, doc?"
>> require 'digest/sha1'
=> true
>> sha1 = Digest::SHA1.hexdigest(store)
=> "bd9dbf5aae1a3862dd1526723246b20206e5fc37"O Git comprime o novo conteúdo com zlib, o que você pode fazer em Ruby com a biblioteca zlib.
Primeiro, você precisa incluir a biblioteca e então executar Zlib::Deflate.deflate() no conteúdo:
>> require 'zlib'
=> true
>> zlib_content = Zlib::Deflate.deflate(store)
=> "x\x9CK\xCA\xC9OR04c(\xCFH,Q\xC8,V(-\xD0QH\xC9O\xB6\a\x00_\x1C\a\x9D"Por último, você irá salvar o seu conteúdo comprimido com zlib em um objeto no disco.
Você irá determinar o caminho do objeto que você quer escrever (sendo os dois primeiros caracteres do valor do SHA-1 o nome do subdiretório, e os últimos 38 caracteres sendo o nome do arquivo dentro desse diretório).
Em Ruby, você pode usar a função FileUtils.mkdir_p() para criar o subdiretório se ele não existir.
Depois, abra o arquivo com File.open() e escreva o conteúdo previamente comprimido com zlib no arquivo chamando write() no file handle resultante:
>> path = '.git/objects/' + sha1[0,2] + '/' + sha1[2,38]
=> ".git/objects/bd/9dbf5aae1a3862dd1526723246b20206e5fc37"
>> require 'fileutils'
=> true
>> FileUtils.mkdir_p(File.dirname(path))
=> ".git/objects/bd"
>> File.open(path, 'w') { |f| f.write zlib_content }
=> 32É isso - você criou um objeto blob do Git válido. Todos os objetos são armazenados do mesmo jeito, apenas com diferentes tipos - em vez da string blob, o cabeçalho começará com commit ou tree. Além disso, ainda que o conteúdo do blob possa ser quase qualquer coisa, o conteúdo do commit e da tree são especificamente formatados.