-
1. Começando
- 1.1 Sobre Controle de Versão
- 1.2 Uma Breve História do Git
- 1.3 O Básico do Git
- 1.4 A Linha de Comando
- 1.5 Instalando o Git
- 1.6 Configuração Inicial do Git
- 1.7 Pedindo Ajuda
- 1.8 Sumário
-
2. Fundamentos de Git
-
3. Branches no Git
-
4. Git no servidor
- 4.1 Os Protocolos
- 4.2 Getting Git on a Server
- 4.3 Gerando Sua Chave Pública SSH
- 4.4 Setting Up the Server
- 4.5 Git Daemon
- 4.6 Smart HTTP
- 4.7 GitWeb
- 4.8 GitLab
- 4.9 Third Party Hosted Options
- 4.10 Sumário
-
5. Distributed Git
-
6. GitHub
- 6.1 Configurando uma conta
- 6.2 Contribuindo em um projeto
- 6.3 Maintaining a Project
- 6.4 Managing an organization
- 6.5 Scripting GitHub
- 6.6 Summary
-
7. Git Tools
- 7.1 Revision Selection
- 7.2 Interactive Staging
- 7.3 Stashing and Cleaning
- 7.4 Signing Your Work
- 7.5 Searching
- 7.6 Rewriting History
- 7.7 Reset Demystified
- 7.8 Advanced Merging
- 7.9 Rerere
- 7.10 Debugging with Git
- 7.11 Submodules
- 7.12 Bundling
- 7.13 Replace
- 7.14 Credential Storage
- 7.15 Summary
-
8. Customizing Git
- 8.1 Git Configuration
- 8.2 Git Attributes
- 8.3 Git Hooks
- 8.4 An Example Git-Enforced Policy
- 8.5 Summary
-
9. Git and Other Systems
- 9.1 Git as a Client
- 9.2 Migrating to Git
- 9.3 Summary
-
10. Funcionamento Interno do Git
- 10.1 Encanamento e Porcelana
- 10.2 Objetos do Git
- 10.3 Referências do Git
- 10.4 Packfiles
- 10.5 The Refspec
- 10.6 Transfer Protocols
- 10.7 Maintenance and Data Recovery
- 10.8 Variáveis de ambiente
- 10.9 Sumário
-
A1. Appendix A: Git em Outros Ambientes
- A1.1 Graphical Interfaces
- A1.2 Git in Visual Studio
- A1.3 Git in Eclipse
- A1.4 Git in Bash
- A1.5 Git in Zsh
- A1.6 Git in Powershell
- A1.7 Resumo
-
A2. Appendix B: Embedding Git in your Applications
- A2.1 Command-line Git
- A2.2 Libgit2
- A2.3 JGit
-
A3. Appendix C: Git Commands
- A3.1 Setup and Config
- A3.2 Getting and Creating Projects
- A3.3 Basic Snapshotting
- A3.4 Branching and Merging
- A3.5 Sharing and Updating Projects
- A3.6 Inspection and Comparison
- A3.7 Debugging
- A3.8 Patching
- A3.9 Email
- A3.10 External Systems
- A3.11 Administration
- A3.12 Plumbing Commands
5.2 Distributed Git - Contribuindo com um Projeto
Contribuindo com um Projeto
A principal dificuldade em descrever como contribuir com um projeto é a numerosa quantidade de maneiras de contribuir. Já que Git é muito flexível, as pessoas podem e trabalham juntas de muitas maneiras, sendo problemático descrever como você deve contribuir — cada projeto é um pouco diferente. Algumas das variáveis envolvidas são a quantidade de colaboradores ativos, o fluxo de trabalho escolhido, sua permissão para fazer commit, e possivelmente o método de contribuição externa.
A primeira variável é a quantidade de colaboradores ativos — quantos usuários estão ativamente contribuindo para o código deste projeto, e em que frequência? Em muitas circunstâncias você terá dois ou três desenvolvedores com alguns commites por dia, ou possivelmente menos em projetos meio dormentes. Para grandes companhias ou projetos, o número de desenvolvedores pode estar nas centenas, com centenas ou milhares de commites chegando todos os dias. Isto é importante porque com mais e mais desenvolvedores, você se depara com mais problemas para certificar-se que seu código é aplicado diretamente ou pode ser facilmente integrado. Alterações que você entrega podem se tornar obsoletas ou severamente quebrar pelo trabalho que é mesclado enquanto você trabalha ou enquanto suas mudanças estão esperando para serem aprovadas e aplicadas. Como você pode manter seu código consistentemente atualizado e seus commites válidos?
A próxima variável é o fluxo de trabalho em uso no projeto. Ele é centralizado, com cada desenvolvedor tendo permissões de escrita iguais para o código principal? O projeto tem um mantenedor ou coordenador que checa todos os patches? Todos os patches são revisados e aprovados pelos colegas? Você está envolvido neste processo? Um sistema de tenentes está estabelecido, e você tem que enviar seu trabalho para eles antes?
A próxima variável é sua permissão de commit. O fluxo de trabalho necessário para contribuir ao projeto é muito diferente se você tem permissão de escrita ao projeto ou não tem. Se você não tem permissão de escrita, como o projeto costuma aceitar o trabalho dos colaboradores? Existe algum tipo de norma? Quanto trabalho você está enviando por vez? Com que frequência?
Todas estas questões podem afetar como você contribui efetivamente para o projeto e que fluxos de trabalho são adequados ou possíveis para você. Iremos abordar aspectos de cada uma delas em uma série de estudos de caso, indo do simples ao mais complexo; você deve ser capaz de construir fluxos de trabalho específicos para suas necessidades com estes exemplos.
Diretrizes para Fazer Commites
Antes de vermos estudos de casos específicos, uma observação rápida sobre mensagens de commit.
Ter uma boa diretriz para criar commites e a seguir facilita muito trabalhar com Git e colaborar com outros.
O projeto Git fornece um documento que dá várias dicas boas para criar commites ao enviar patches — você pode lê-lo no código fonte do Git no arquivo Documentation/SubmittingPatches.
Primeiro, seus envios não devem conter nenhum espaço em branco não proposital.
Git fornece uma maneira fácil de checar isto — antes de você fazer um commit, execute git diff --check, que identifica possíveis espaços em branco indesejados e os lista pra você.
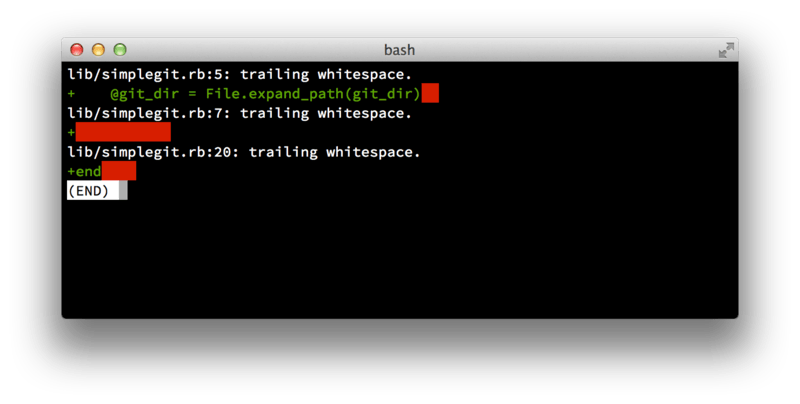
git diff --check
Se você executar este comando antes do commit, você perceberá se está prestes a enviar espaços em branco problemáticos que podem irritar os outros desenvolvedores.
Depois tente fazer cada commit como um conjunto lógico de mudanças.
Se possível, tente digerir suas modificações — não programe o final de semana inteiro em cinco diferentes problemas e então publique tudo em um commit massivo na segunda-feira.
Mesmo que você não publique durante o fim de semana, use a área de stage na segunda-feira para dividir seu trabalho em ao menos um commit por assunto, com uma mensagem útil em cada commit.
Se algumas alterações modificarem o mesmo arquivo, tente executar git add --patch para colocar na área de stage os arquivos parcialmente (explicado em detalhes em Interactive Staging).
O retrato do projeto no final do branch é idêntico você fazendo um commit ou cinco, desde que todas as mudanças forem eventualmente adicionadas, então tente fazer as coisas mais fáceis para seus colegas desenvolvedores quando eles tiverem que revisar suas mudanças.
Esta abordagem também facilita retirar ou reverter uma das alterações se você precisar depois. Rewriting History descreve vários truques úteis do Git para reescrever o histórico e colocar interativamente arquivos na área de stage — utilize estas ferramentas para criar um histórico limpo e compreensível antes de enviar o trabalho para alguém.
A última coisa para ter em mente é a mensagem do commit. Manter o hábito de criar boas mensagens de commit facilita muito usar e colaborar com o Git. Como regra geral, suas mensagens devem começar com uma única linha que não tem mais que 50 caracteres e descreve as alterações concisamente, seguida de uma linha em branco, seguida de uma explicação mais detalhada. O projeto Git requer que esta explicação mais detalhada inclua sua motivação para a mudança e compare sua implementação com o comportamento anterior — esta é uma boa diretriz para seguir. Escreva sua mensagem de commit no imperativo: "Consertar o bug" e não "Bug consertado" ou "Conserta bug." Tem um modelo que você pode seguir, que adaptamos ligeiramente daqui escrito originalmente por Tim Pope:
Resumo curto (50 caracteres ou menos), com maiúsculas.
Mais texto explicativo, se necessário. Desenvolva por 72
caracteres aproximadamente. Em alguns contextos, a primeira linha é tratada como o
assunto do email e o resto do texto como o corpo. A linha
em branco separando o assunto do corpo é crítica (a não ser que você omita
o corpo inteiro); ferramentas como _rebase_ irão te confundir se você unir as
duas partes.
Escreva sua mensagem de commit no imperativo: "Consertar o bug" e não "Bug consertado"
ou "Conserta bug". Esta convenção combina com as mensagens de commit geradas
por comandos como `git merge` e `git revert`.
Parágrafos seguintes veem depois de linhas em branco.
- Marcadores são ok, também
- Normalmente um hífen ou asterisco é usado para o marcador, seguido de um
único espaço, com linhas em branco entre eles, mas os protocolos podem variar aqui
- Utilize recuos alinhadosSe todas as suas mensagens de commit seguirem este modelo, as coisas serão muito mais fáceis para você e os desenvolvedores com que trabalha.
O projeto Git tem mensagens de commit bem formatadas - tente executar git log --no-merges nele para ver o que um projeto com histórico de commit bem feito se parece.
|
Note
|
Faça o que digo, não faça o que faço.
Para o bem da concisão, muitos dos exemplos neste livro não tem mensagens de commit bem formatas como esta; ao invés, nós simplesmente usamos a opção Resumindo, faça o que digo, não faça o que faço. |
Time Pequeno Privado
A configuração mais simples que você deve encontrar é um projeto privado com um ou dois outros desenvolvedores. ``Privado,`` neste contexto, significa código fechado — não acessível ao mundo exterior. Você e os outros desenvolvedores têm permissão para publicar no repositório.
Neste ambiente, você pode seguir um fluxo de trabalho similar ao que faria usando Subversion ou outro sistema centralizado.
Você ainda tem vantagens como fazer commites offline e fazer branches e mesclagens infinitamente mais simples, mas o fluxo de trabalho pode ser bastante semelhante; a principal diferença é que mesclar acontece no lado do cliente ao invés do servidor na hora do commit.
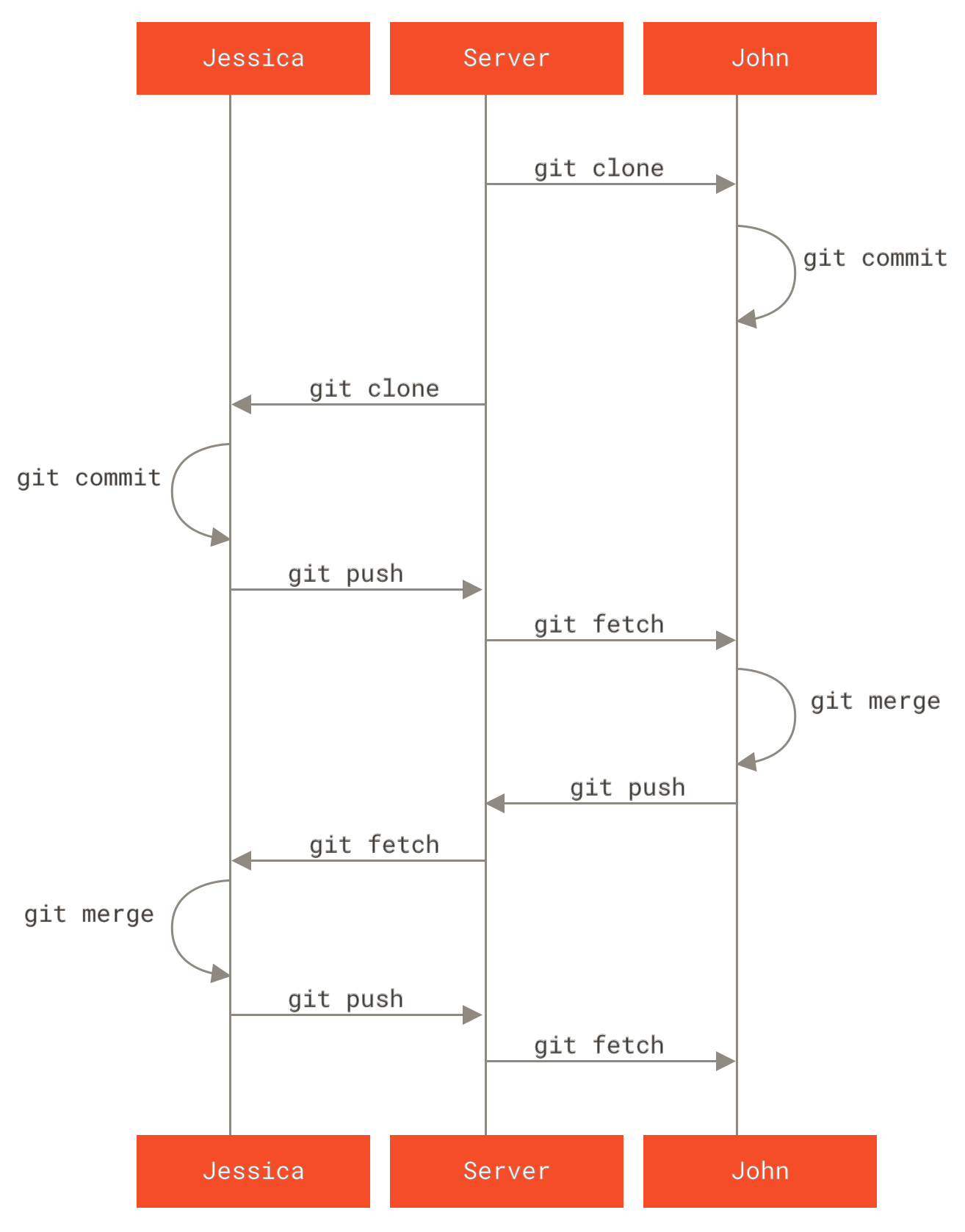
Veremos o que pode acontecer quando dois desenvolvedores começam a trabalhar juntos em um repositório compartilhado.
O primeiro desenvolvedor, John, clona o repositório, faz uma alteração e um commit localmente.
O protocolo de mensagens foi substituído por ... nestes exemplos por simplificação.
# Máquina do John
$ git clone john@githost:simplegit.git
Cloning into 'simplegit'...
...
$ cd simplegit/
$ vim lib/simplegit.rb
$ git commit -am 'Remover valor padrão inválido'
[master 738ee87] Remover valor padrão inválido
1 files changed, 1 insertions(+), 1 deletions(-)O segundo desenvolvedor, Jessica, faz a mesma coisa — clona o repositório e faz um commit de uma alteração:
# Computador da Jessica
$ git clone jessica@githost:simplegit.git
Cloning into 'simplegit'...
...
$ cd simplegit/
$ vim FAZER
$ git commit -am 'Adicionar tarefa para reiniciar'
[master fbff5bc] Adicionar tarefa para reiniciar
1 files changed, 1 insertions(+), 0 deletions(-)Agora, Jessica dá um push do seu trabalho no servidor, o que funciona bem:
# Computador da Jessica
$ git push origin master
...
To jessica@githost:simplegit.git
1edee6b..fbff5bc master -> masterA última linha do resultado acima mostra uma mensagem de retorno útil da operação push.
O formato básico é <velharef>..<novaref> daref -> pararef, onde velharef significa velha referência, novaref significa a nova referência, daref é o nome da referência local que está sendo publicada, e pararef é o nome da referência remota sendo atualizada.
Você verá resultados semelhantes como este nas discussões seguintes, então ter uma ideia básica do significado irá ajudá-lo entender os vários estados dos repositórios.
Mais detalhes estão disponíveis na documentação aqui git-push.
Continuando com este exemplo, pouco depois, John faz algumas modificações, um commit no seu repositório local, e tenta dar um push no mesmo servidor:
# Máquina do John
$ git push origin master
To john@githost:simplegit.git
! [rejected] master -> master (non-fast forward)
error: failed to push some refs to 'john@githost:simplegit.git'Neste caso, o push do John falhou por causa das alterações do push que a Jessica fez antes. Isto é especialmente importante de entender se você está acostumado ao Subversion, pois notará que os dois desenvolvedores não editaram o mesmo arquivo. Embora Subversion automaticamente faz uma mesclagem no servidor se arquivos diferentes foram editados, com Git, você deve primeiro mesclar os commites localmente. Em outras palavras, John deve primeiro buscar (fetch) as modificações anteriores feitas pela Jessica e mesclá-las no seu repositório local antes que ele possa fazer o seu push.
Como um passo inicial, John busca o trabalho de Jessica (apenas buscar o trabalho da Jessica, ainda não mescla no trabalho do John):
$ git fetch origin
...
From john@githost:simplegit
+ 049d078...fbff5bc master -> origin/masterNeste ponto, o repositório local do John se parece com isso:
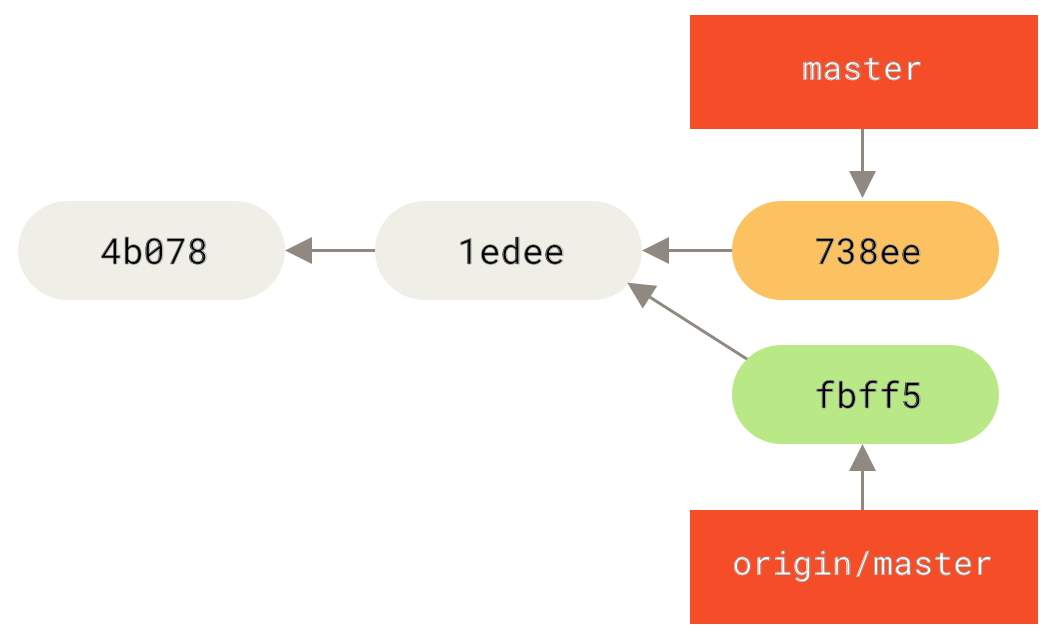
Agora John pode mesclar com o trabalho da Jessica que ele buscou no seu local de trabalho:
$ git merge origin/master
Merge made by the 'recursive' strategy.
FAZER | 1 +
1 files changed, 1 insertions(+), 0 deletions(-)Contanto que a mesclagem local seja tranquila, o histórico atualizado do John será parecido com isto:
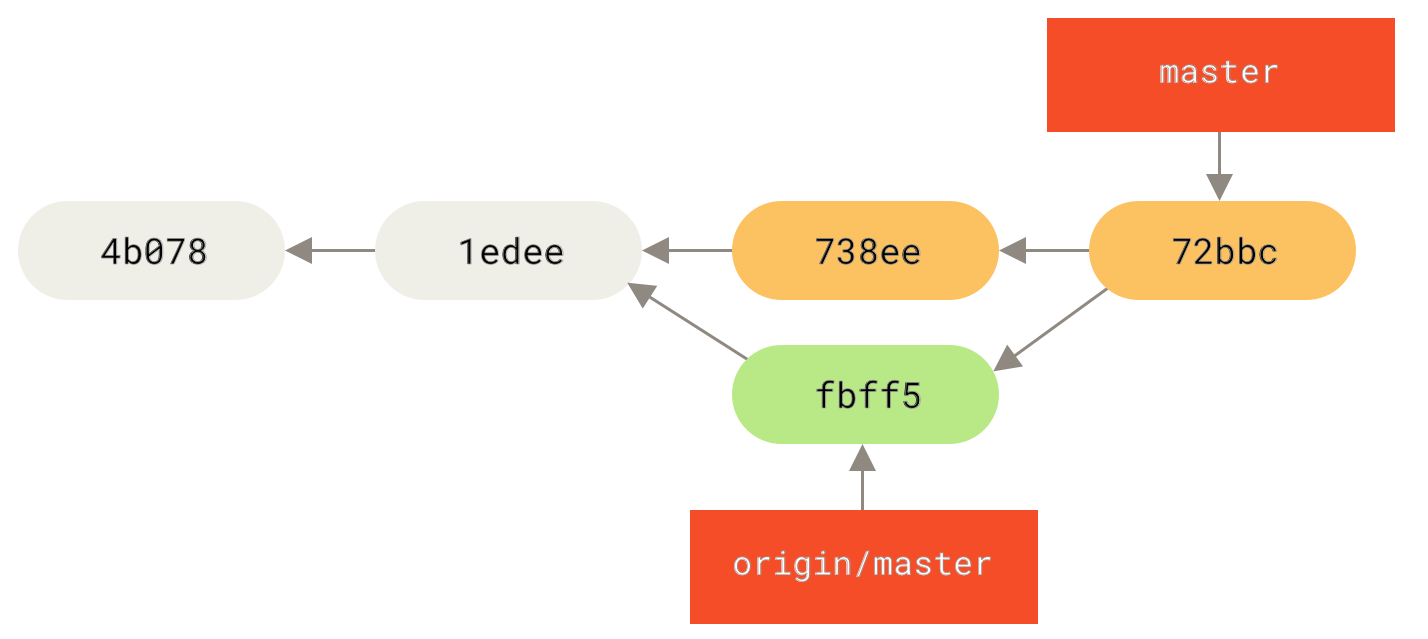
origin/master
Neste ponto, John deve querer testar este código novo para se certificar que o trabalho da Jessica não afete o seu e, desde que tudo corra bem, ele pode finalmente publicar o novo trabalho combinado no servidor:
$ git push origin master
...
To john@githost:simplegit.git
fbff5bc..72bbc59 master -> masterNo fim, o histórico de commit do John ficará assim:
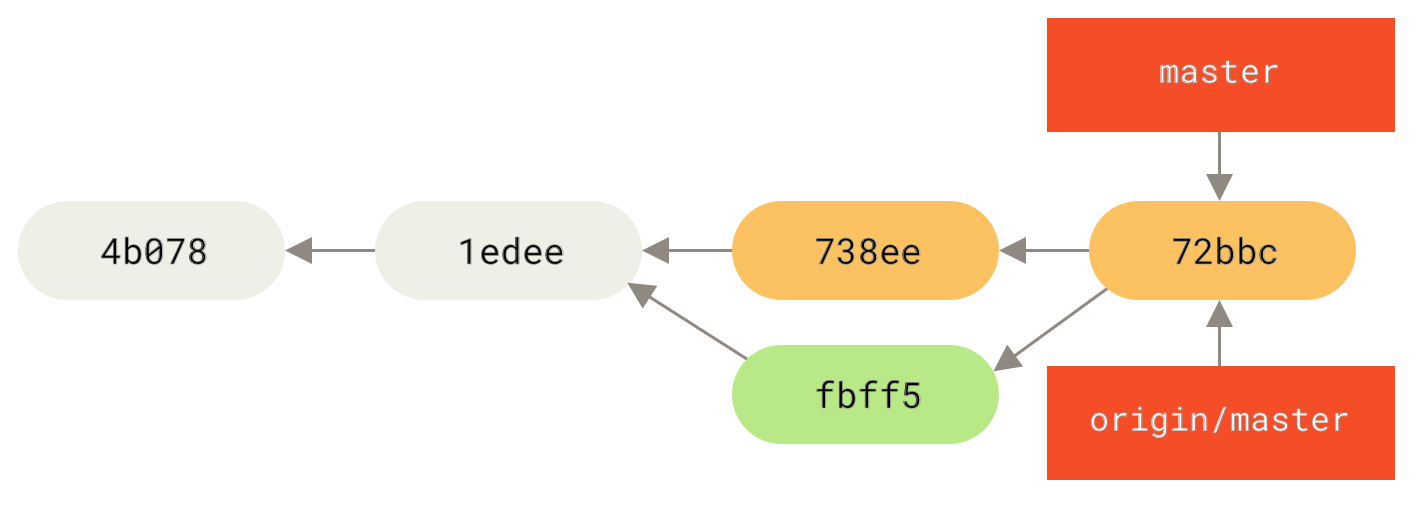
origin
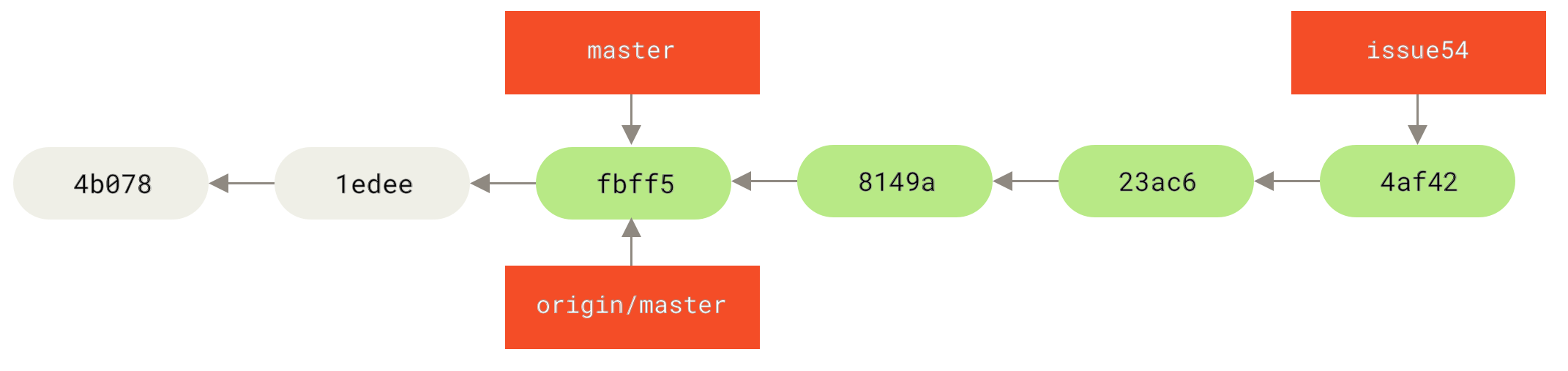
Enquanto isso, Jessica criou um novo branch chamado issue54, e fez três commites naquele branch.
Ela ainda não buscou as alterações do John, então o histórico de commites dela se parece com isso:
De repente, Jessica percebe que o John publicou um trabalho novo no servidor e ela quer dar uma olhada, então ela busca todo o novo conteúdo do servidor que ela ainda não tem:
# Máquina da Jessica
$ git fetch origin
...
From jessica@githost:simplegit
fbff5bc..72bbc59 master -> origin/masterIsto baixa o trabalho que John publicou enquanto isso. O histórico da Jessica agora fica assim:
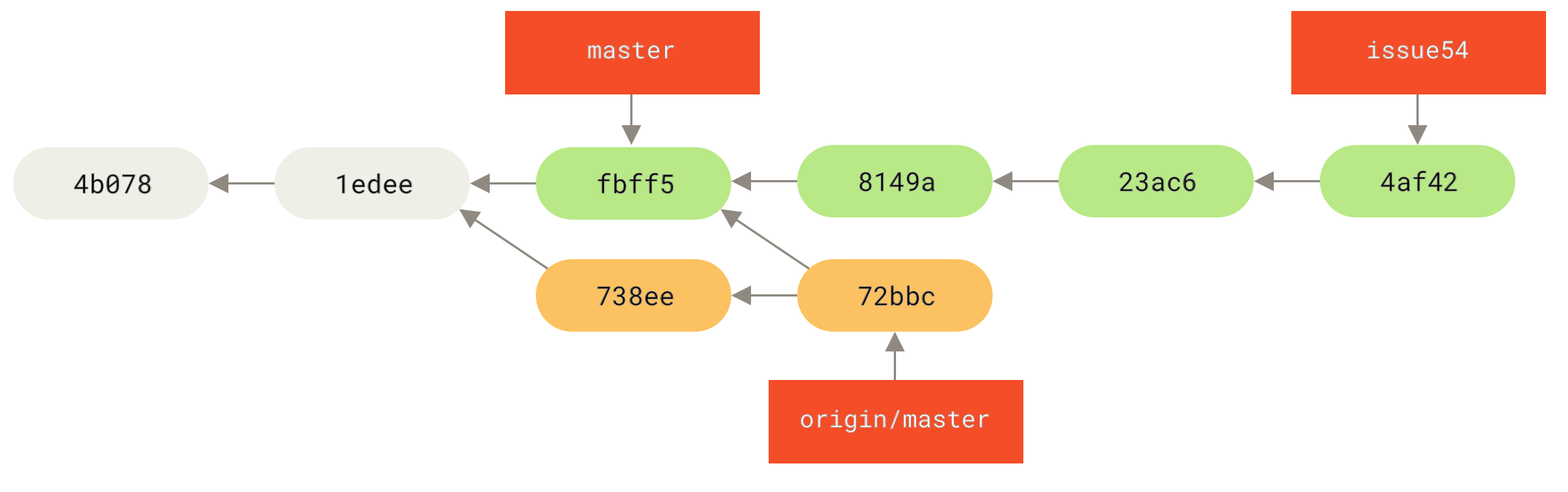
Jessica acha que seu branch atual está pronto, mas quer saber que parte do trabalho que buscou do John ela deve combinar com o seu para publicar.
Ela executa git log para encontrar:
$ git log --no-merges issue54..origin/master
commit 738ee872852dfaa9d6634e0dea7a324040193016
Author: John Smith <jsmith@example.com>
Date: Fri May 29 16:01:27 2009 -0700
Remover valor padrão inválidoA sintaxe issue54..origin/master é um filtro de log que pede ao Git mostrar apenas estes commites que estão no branch seguinte (neste caso origin/master) e não estão no primeiro branch (neste caso issue54).
Iremos cobrir esta sintaxe em detalhes em Commit Ranges.
Do resultado acima, podemos ver que há um único commit que John fez e Jessica não mesclou no trabalho local dela.
Se ela mesclar origin/master, aquele é o único commit que irá modificar seu trabalho local.
Agora, Jessica pode mesclar seu trabalho atual no branch master dela, mesclar o trabalho de John (origin/master) no seu branch master, e então publicar devolta ao servidor.
Primeiro (tendo feito commit de todo o trabalho no branch atual dela issue54), Jessica volta para o seu branch master preparando-se para a integração de todo este trabalho:
$ git checkout master
Switched to branch 'master'
Your branch is behind 'origin/master' by 2 commites, and can be fast-forwarded.Jessica pode mesclar tanto origin/master ou issue54 primeiro — ambos estão adiantados, então a ordem não importa.
O retrato final deve ser idêntico não importando a ordem que ela escolher; apenas o histórico será diferente.
Ela escolhe mesclar o branch issue54 antes:
$ git merge issue54
Updating fbff5bc..4af4298
Fast forward
README | 1 +
lib/simplegit.rb | 6 +++++-
2 files changed, 6 insertions(+), 1 deletions(-)Nenhum problema ocorre; como você pode ver foi uma simples combinação direta.
Jessica agora completa o processo local de combinação integrando o trabalho de John buscado anteriormente que estava esperando no branch origin/master:
$ git merge origin/master
Auto-merging lib/simplegit.rb
Merge made by the 'recursive' strategy.
lib/simplegit.rb | 2 +-
1 files changed, 1 insertions(+), 1 deletions(-)Tudo combina bem, e o histórico de Jessica agora se parece com isto:
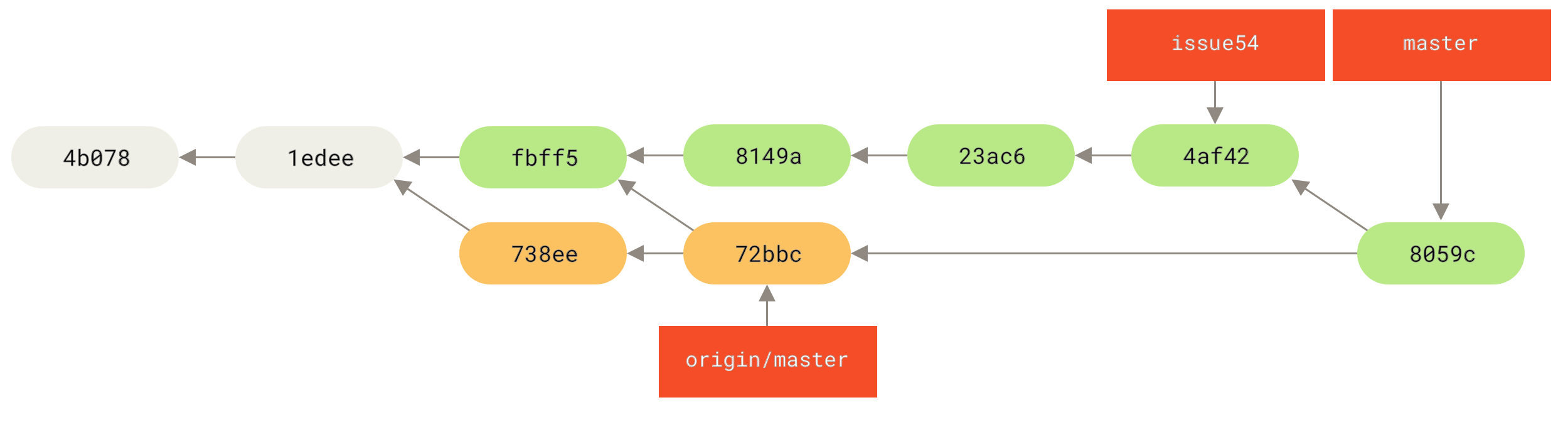
Agora origin/master é acessível para o branch master de Jessica, então ela deve ser capaz de publicar com sucesso (assumindo que John não publicou nenhuma outra modificação enquanto isso):
$ git push origin master
...
To jessica@githost:simplegit.git
72bbc59..8059c15 master -> masterCada desenvolvedor fez alguns commites e mesclou ao trabalho do outro com sucesso.
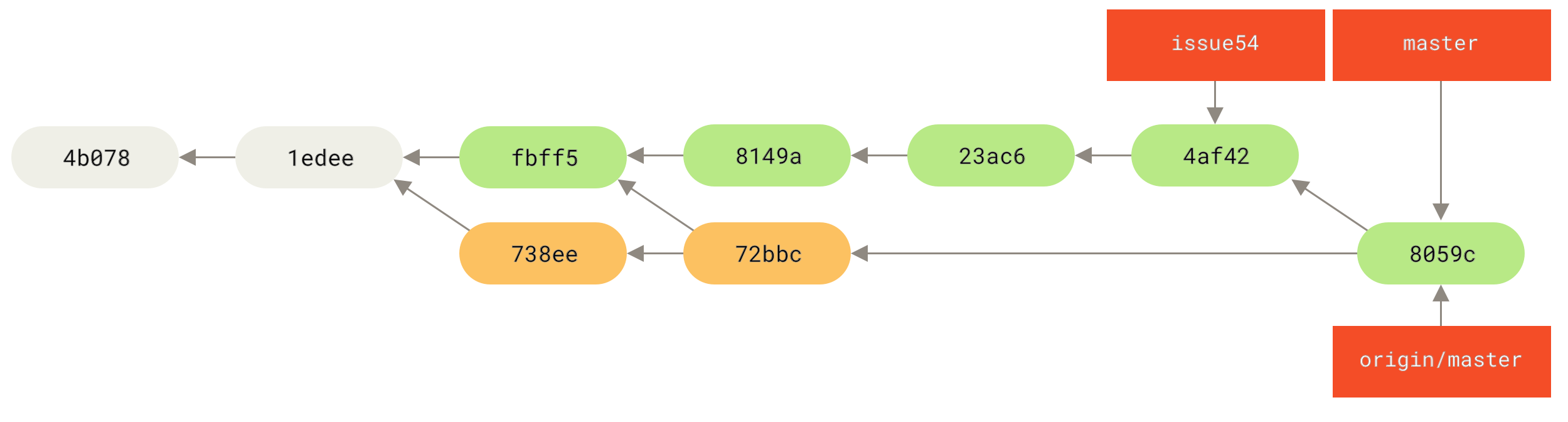
Este é um dos mais simples fluxos de trabalho.
Você trabalha um pouco (normalmente em um branch separado), e mescla este trabalho no seu branch master quando está pronto para ser integrado.
Quando você quiser compartilhar este trabalho, você busca e mescla seu master ao origin/master se houve mudanças, e finalmente publica no branch master do servidor.
A sequência comum é mais ou menos assim:
Time Privado Gerenciado
No próximo cenário, você irá observar os papéis de um colaborador em um grande grupo privado. Você irá aprender como trabalhar em um ambiente onde pequenos grupos colaboram em componentes, então as contribuições deste time são integradas por outra equipe.
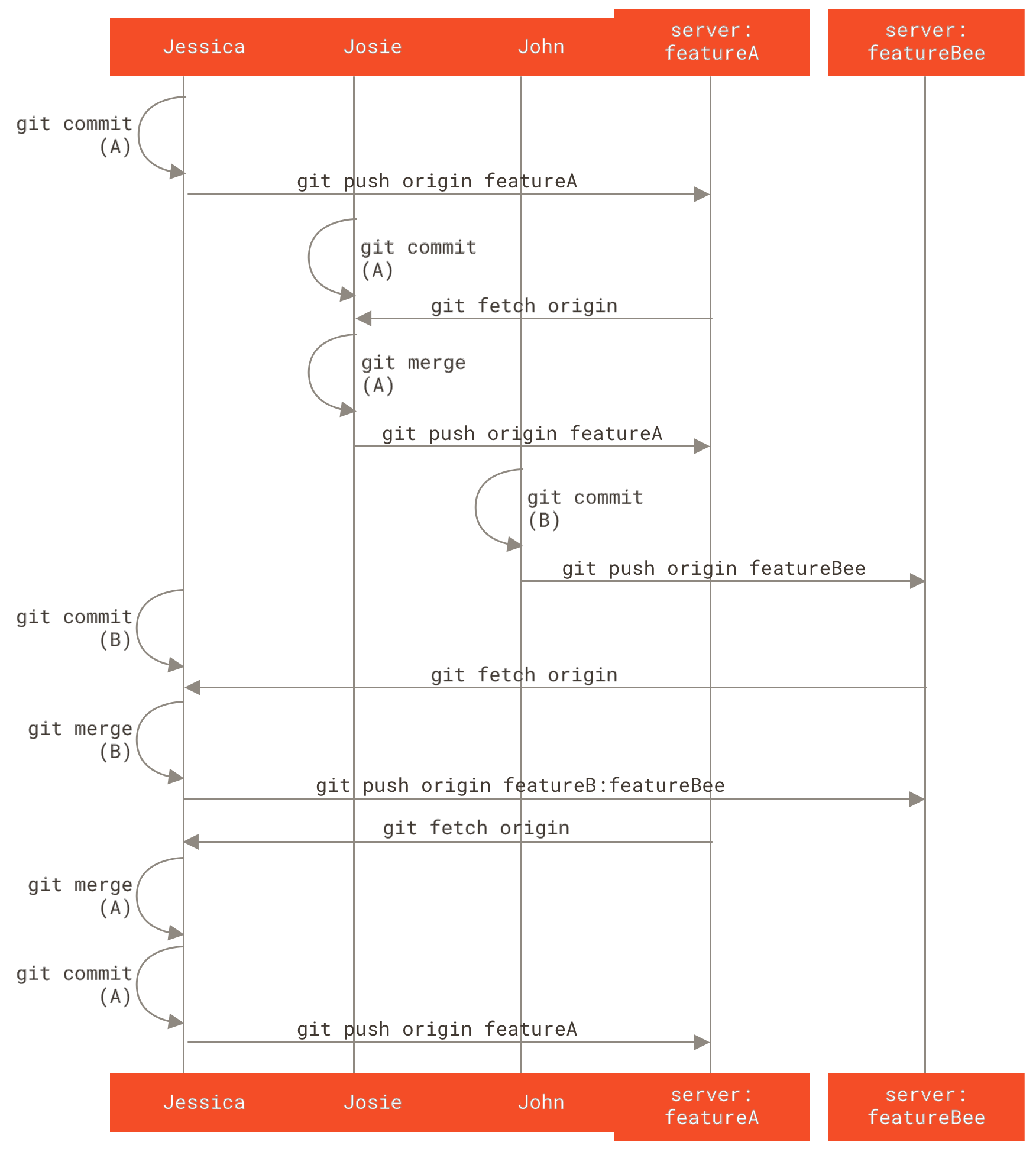
Digamos que John e Jessica estão trabalhando juntos em um componente (chamado featureA), enquanto Jessica e uma terceira desenvolvedora, Josie, estão trabalhando num outro (digamos featureB).
Neste caso, a companhia está usando um tipo de fluxo de trabalho gerenciado onde o trabalho de grupos isolados é integrado apenas por certos engenheiros, e o branch master do repositório principal pode ser atualizado apenas por estes engenheiros.
Neste cenário, todo trabalho é feito em branches da equipe e publicados depois pelos coordenadores.
Vamos acompanhar o fluxo de trabalho da Jessica enquanto ela trabalha em seus dois componentes, colaborando em paralelo com dois desenvolvedores neste ambiente.
Assumindo que ela já tem seu repositório clonado, ela decide trabalhar no featureA antes.
Ela cria um novo branch para o componente e trabalha um pouco nele:
# Máquina da Jessica
$ git checkout -b featureA
Switched to a new branch 'featureA'
$ vim lib/simplegit.rb
$ git commit -am 'Adicionar limite a função log'
[featureA 3300904] Adicionar limite a função log
1 files changed, 1 insertions(+), 1 deletions(-)Neste ponto, ela precisa compartilhar seu trabalho com John, então ela publica seus commites no branch featureA do servidor.
Jessica não tem permissão de publicar no branch master — apenas os coordenadores tem — então ela publica em outro branch para trabalhar com John:
$ git push -u origin featureA
...
To jessica@githost:simplegit.git
* [new branch] featureA -> featureAJessica comunica John que publicou alguma coisa no branch chamado featureA e ele pode dar uma olhada agora.
Enquanto ela espera John responder, Jessica decide começar a trabalhar no featureB com Josie.
Para começar, ela cria um novo branch para o componente, baseando-se no branch master do servidor:
# Máquina da Jessica
$ git fetch origin
$ git checkout -b featureB origin/master
Switched to a new branch 'featureB'Agora Jessica faz alguns commites no branch featureB:
$ vim lib/simplegit.rb
$ git commit -am 'Tornar a função ls-tree recursiva'
[featureB e5b0fdc] Tornar a função ls-tree recursiva
1 files changed, 1 insertions(+), 1 deletions(-)
$ vim lib/simplegit.rb
$ git commit -am 'Adicionar ls-files'
[featureB 8512791] Adicionar ls-files
1 files changed, 5 insertions(+), 0 deletions(-)O repositório de Jessica agora fica assim:
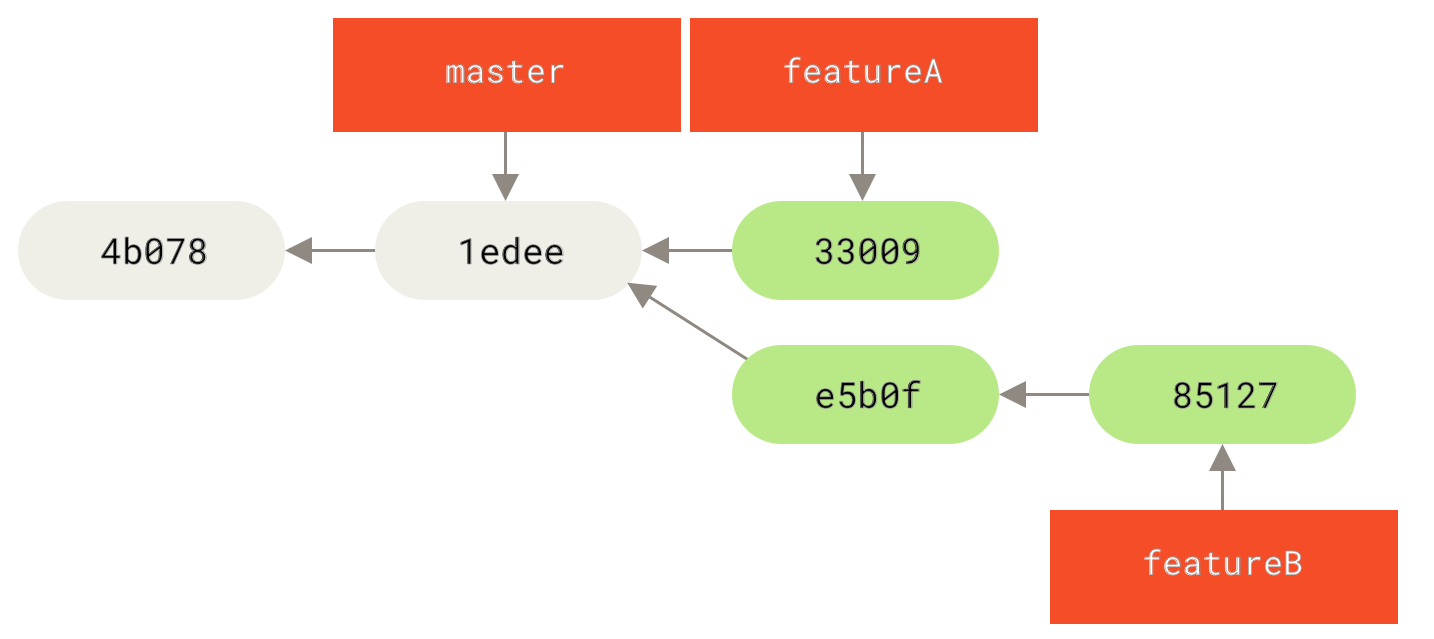
Ela já está pronta para publicar seu trabalho, mas recebe um email de Josie dizendo que um branch contendo um featureB inicial já foi publicado no servidor como featureBee.
Jessica precisa combinar estas alterações com as suas antes que ela possa publicar seu trabalho no servidor.
Jessica primeiro busca as mudanças de Josie com git fetch:
$ git fetch origin
...
From jessica@githost:simplegit
* [new branch] featureBee -> origin/featureBeeAssumindo que Jessica ainda está no seu branch featureB, ela pode agora incorporar o trabalho de Josie neste branch com git merge:
$ git merge origin/featureBee
Auto-merging lib/simplegit.rb
Merge made by the 'recursive' strategy.
lib/simplegit.rb | 4 ++++
1 files changed, 4 insertions(+), 0 deletions(-)Neste ponto, Jessica quer publicar todo este featureB mesclado no servidor, mas ela não quer simplesmente publicar no seu branch featureB.
Ao invés disso, como Josie já começou um branch featureBee, Jessica quer publicar neste branch, que ela faz assim:
$ git push -u origin featureB:featureBee
...
To jessica@githost:simplegit.git
fba9af8..cd685d1 featureB -> featureBeeIsto é chamado de refspec.
Veja The Refspec para uma discussão mais detalhada sobre os refspecs do Git e as diferentes coisas que você pode fazer com eles.
Também perceba a flag -u; isto é abreviação de --set-upstream, que configura os branches para facilitar publicar e baixar depois.
De repente, Jessica recebe um email de John, contando que publicou algumas modificações no branch featureA no qual eles estavam colaborando, e ele pede a Jessica para dar uma olhada.
Denovo, Jessica executa um simples git fetch para buscar todo novo conteúdo do servidor, incluindo (é claro) o último trabalho de John:
$ git fetch origin
...
From jessica@githost:simplegit
3300904..aad881d featureA -> origin/featureAJessica pode exibir o log do novo trabalho de John comparando o conteúdo do branch featureA recentemente buscado com sua cópia local do mesmo branch:
$ git log featureA..origin/featureA
commit aad881d154acdaeb2b6b18ea0e827ed8a6d671e6
Author: John Smith <jsmith@example.com>
Date: Fri May 29 19:57:33 2009 -0700
Aumentar resultados do log para 30 de 25Se Jessica gostar do que vê, ela pode integrar o recente trabalho de John no seu branch featureA local com:
$ git checkout featureA
Switched to branch 'featureA'
$ git merge origin/featureA
Updating 3300904..aad881d
Fast forward
lib/simplegit.rb | 10 +++++++++-
1 files changed, 9 insertions(+), 1 deletions(-)Finalmente, Jessica pode querer fazer algumas pequenas alterações de todo o conteúdo mesclado, então ela está livre para fazer estas mudanças, commitar elas no seu branch featureA local, e publicar o resultado de volta ao servidor:
$ git commit -am 'Adicionar pequeno ajuste ao conteúdo mesclado'
[featureA 774b3ed] Adicionar pequeno ajuste ao conteúdo mesclado
1 files changed, 1 insertions(+), 1 deletions(-)
$ git push
...
To jessica@githost:simplegit.git
3300904..774b3ed featureA -> featureAO histórico de commites da Jessica agora está assim:
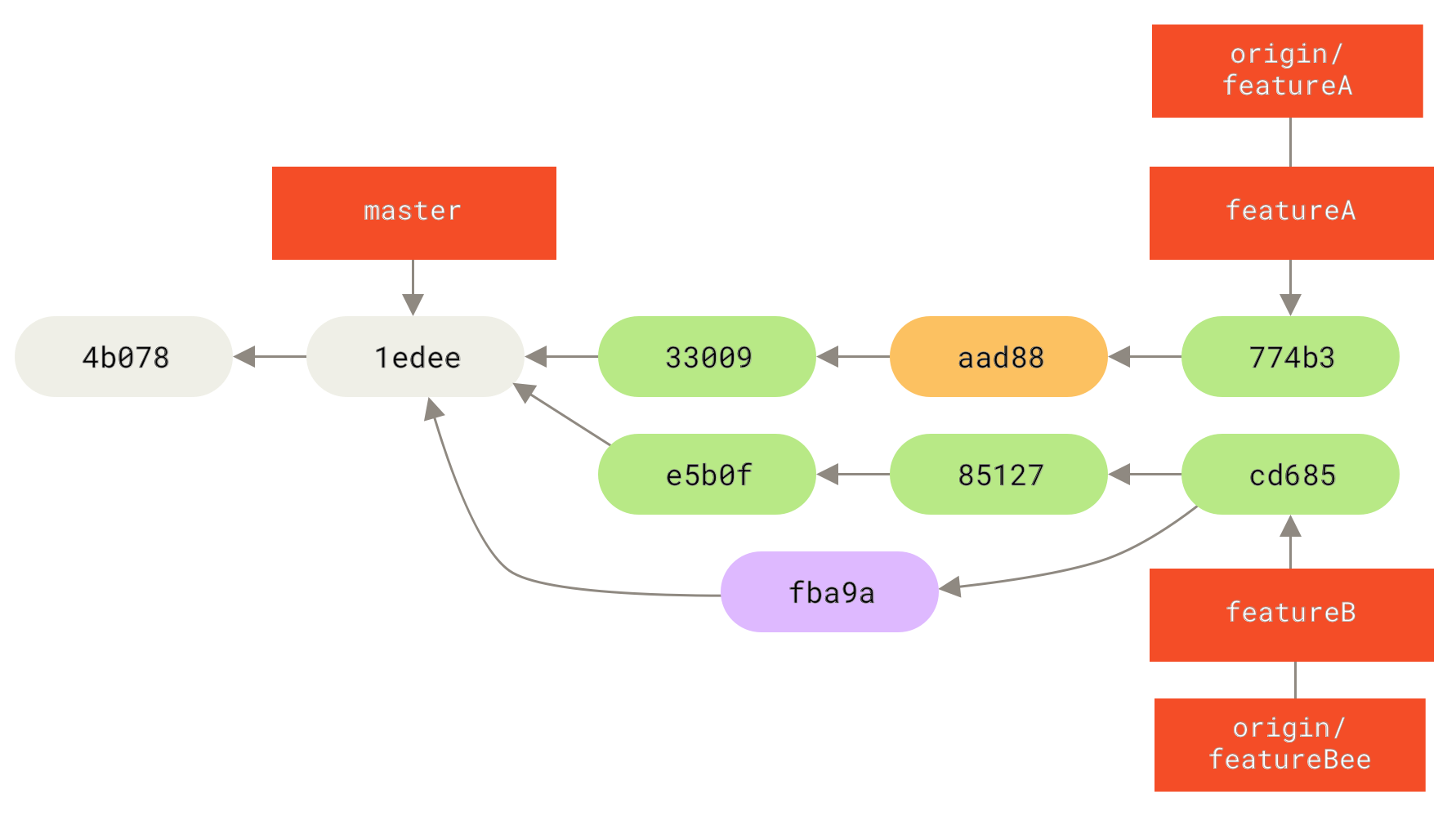
Em algum ponto, Jessica, Josie e John informam os coordenadores que os branches featureA e featureBee no servidor estão prontos para serem integrados no código principal.
Depois dos coordenadores mesclarem estes branches no código principal, um fetch trará o novo commit mesclado, deixando o histórico assim:
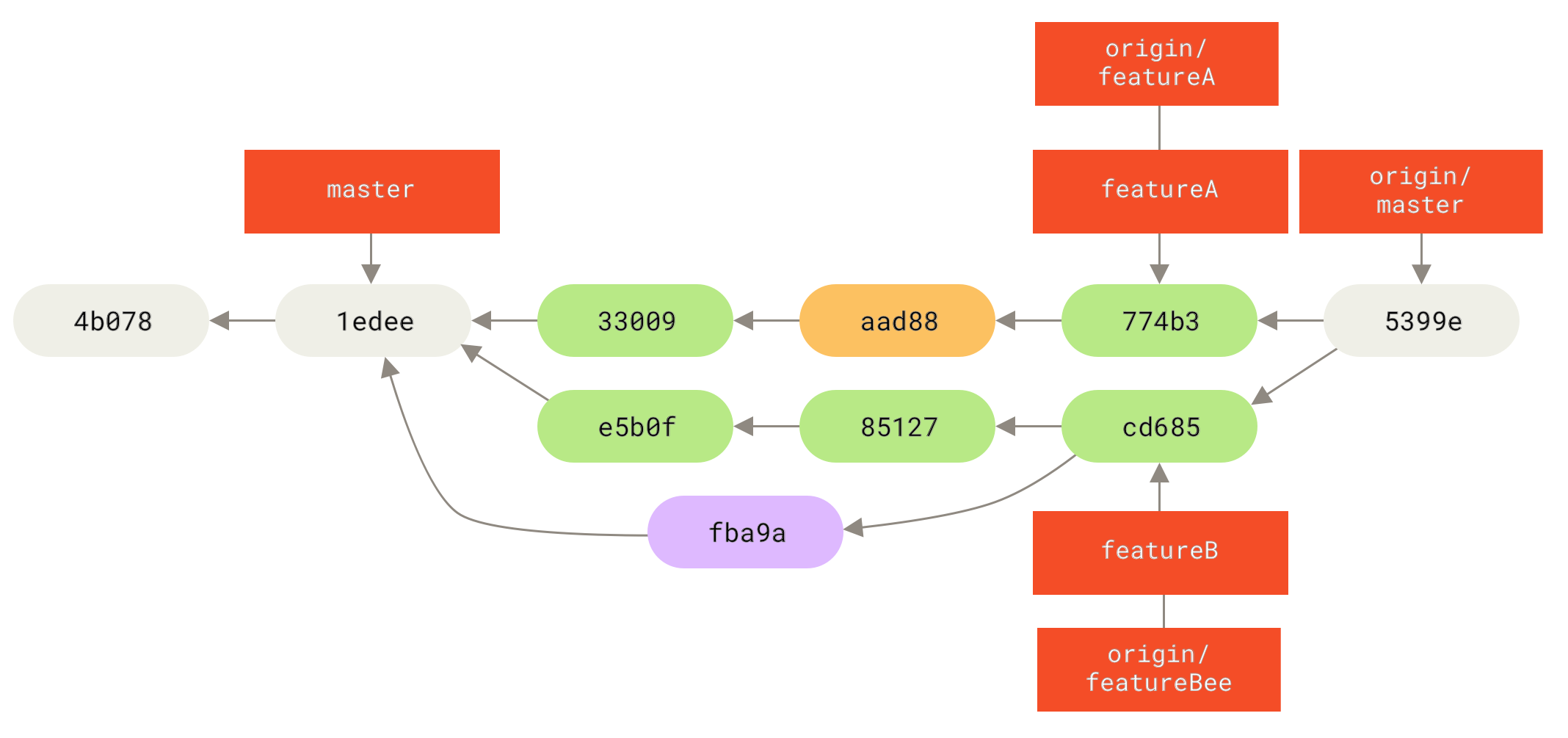
Muitos grupos migraram para o Git pela possibilidade de ter múltiplos times trabalhando em paralelo, combinando as diferentes frentes de trabalho mais tarde no processo. A habilidade de pequenos subgrupos da equipe colaborar através de branches remotos sem necessariamente ter que envolver ou atrasar a equipe inteira é um benefício imenso do Git. A sequência do fluxo de trabalho que você viu aqui é parecida com isto:
Fork de Projeto Público
Colaborando com projetos públicos é um pouco diferente. Como você não tem as permissões para atualizar diretamente branches no projeto, você deve levar seu trabalho aos coordenadores de algum jeito diferente. O primeiro exemplo descreve como contribuir através de forks em um site de hospedagem Git que permite fazer forks facilmente. Muitos sites de hospedagem suportam isto (incluindo GitHub, BitBucket, repo.or.cz, e outros), e muitos mantenedores de projetos esperam este estilo de contribuição. A próxima seção lida com projetos que preferem aceitar patches de contribuição por email.
Primeiro, você provavelmente irá preferir clonar o repositório principal, criar um branch específico para o patch ou série de patchs que está planejando contribuir, e fazer o seu trabalho ali. A sequência fica basicamente assim:
$ git clone <url>
$ cd project
$ git checkout -b featureA
... trabalho ...
$ git commit
... trabalho ...
$ git commit|
Note
|
Você pode querer usar |
Quando seu trabalho no branch é finalizado e você está pronto para mandá-lo para os mantenedores, vá para a página original do projeto e clique no botão “Fork”, criando seu próprio fork editável do projeto.
Você precisa então adicionar a URL deste repositório como um novo repositório remoto do seu repositório local; neste exemplo, vamos chamá-lo meufork:
$ git remote add meufork <url>Você então precisa publicar seu trabalho neste repositório.
É mais fácil publicar o branch em que você está trabalhando no seu repositório fork, ao invés de mesclar este trabalho no seu branch master e publicar assim.
A razão é que se o seu trabalho não for aceito ou for selecionado a dedo (cherry-pick), você não tem que voltar seu branch master (a operação do Git cherry-pick é vista em mais detalhes em Rebasing and Cherry-Picking Workflows).
Se os mantenedores executarem um merge, rebase ou cherry-pick no seu trabalho, você irá eventualmente receber seu trabalho de novo através do repositório deles de qualquer jeito.
Em qualquer um dos casos, você pode publicar seu trabalho com:
$ git push -u meufork featureA
Uma vez que seu trabalho tenha sido publicado no repositório do seu fork, você deve notificar os mantenedores do projeto original que você tem trabalho que gostaria que eles incorporassem no código.
Isto é comumente chamado de pull request, e você tipicamente gera esta requisição ou através do website — GitHub tem seu próprio mecanismo de “Pull Request” que iremos abordar em [ch06-github] — ou você pode executar o comando git request-pull e mandar um email com o resultado para o mantenedor do projeto manualmente.
O comando git request-pull pega o branch base no qual você quer o seu branch atual publicado e a URL do repositório Git de onde você vai buscar, e produz um resumo de todas as mudanças que você está tentando publicar.
Por exemplo, se Jessica quer mandar a John uma pull request, e ela fez dois commites no branch que ela acabou de publicar, ela pode executar:
$ git request-pull origin/master meufork
The following changes since commit 1edee6b1d61823a2de3b09c160d7080b8d1b3a40:
Jessica Smith (1):
Criar nova função
are available in the git repository at:
git://githost/simplegit.git featureA
Jessica Smith (2):
Adicionar limite para a função log
Aumentar a saída do log para 30 de 25
lib/simplegit.rb | 10 +++++++++-
1 files changed, 9 insertions(+), 1 deletions(-)Este resultado pode ser mandado para os mantenedores — ele diz de qual branch o trabalho vem, resume os commites, e identifica onde o novo trabalho será publicado.
Em um projeto em que você não é um mantenedor, é geralmente mais fácil ter um branch principal master sempre rastreando origin/master e fazer seu trabalho em branches separados que você pode facilmente descartar se eles forem rejeitados.
Tendo temas de trabalho isolados em branches próprios também facilita para você realocar seu trabalho se a ponta do repositório principal se mover enquanto trabalha e seus commites não mais puderem ser aplicados diretamente.
Por exemplo, se você quer publicar um segundo trabalho numa outra área do projeto, não continue trabalhando no branch que você acabou de publicar — comece um novo branch apartir do branch no repositório principal master:
$ git checkout -b featureB origin/master
... trabalho ...
$ git commit
$ git push meufork featureB
$ git request-pull origin/master meufork
... email generated request pull to maintainer ...
$ git fetch originAgora, cada um dos seus assuntos está contido em um casulo — igual a um patch na fila — que você pode reescrever, realocar, e modificar sem que os outros assuntos interfiram com ele, deste jeito:
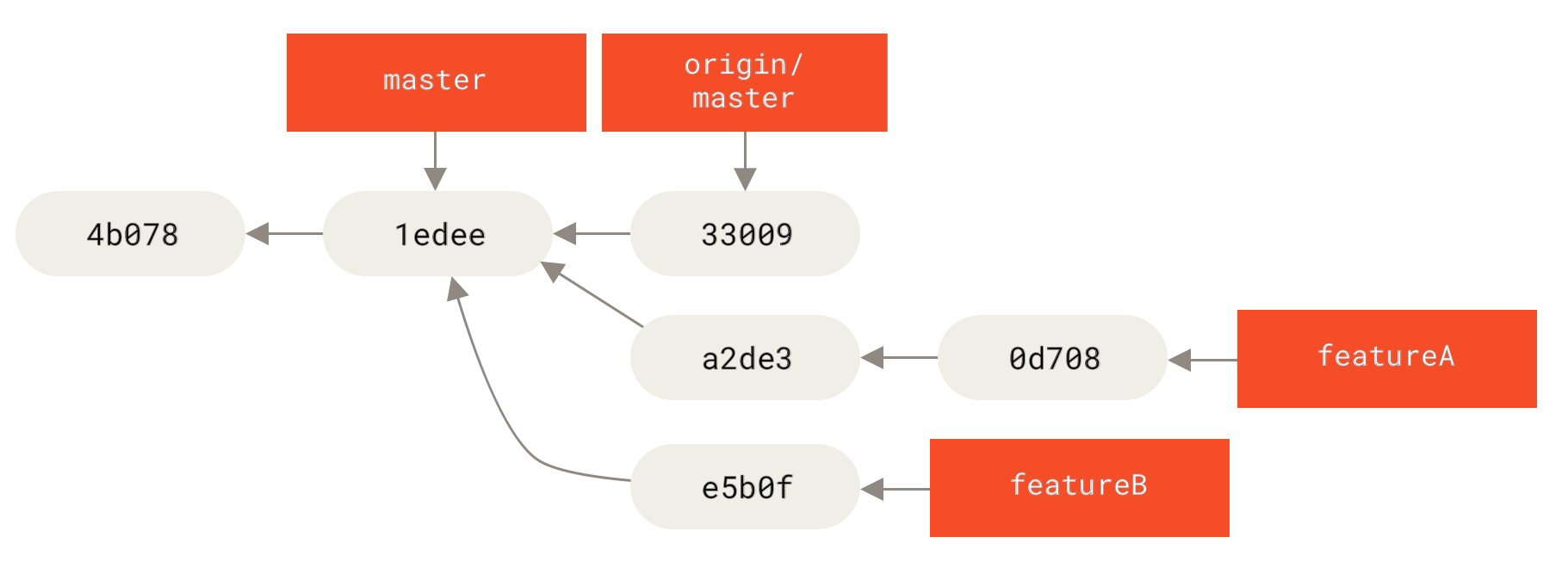
featureB
Digamos que o mantenedor do projeto tenha integrado vários outros patches e, quando tentou seu primeiro branch, seu trabalho não mais combina facilmente.
Neste caso, você pode tentar realocar seu branch no topo de origin/master, resolver os conflitos para o mantenedor, e então republicar suas alterações:
$ git checkout featureA
$ git rebase origin/master
$ git push -f meufork featureAIsto reescreve seu histórico que agora fica assim Histórico de commites depois do trabalho em featureA.
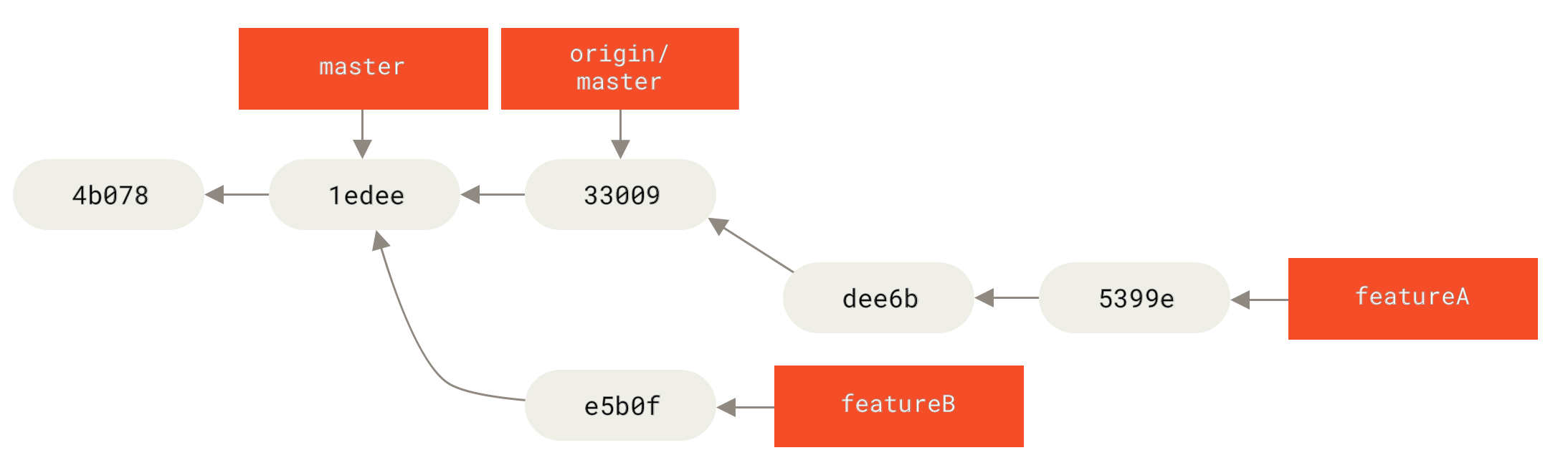
featureA
Como você realocou seu branch, você deve especificar -f para seu comando push substituir o branch featureA no servidor com um commit que não é um descendente dele.
Uma alternativa seria publicar seu novo trabalho em um branch diferente no servidor (talvez chamado featureAv2).
Vamos olhar um outro cenário possível: o mantenedor viu seu trabalho no seu branch secundário e gosta do conceito mas gostaria que você mudasse um detalhe de implementação.
Você aproveita esta oportunidade para basear seu trabalho no branch master do projeto atual.
Você inicia um novo branch baseado no branch origin/master atual, compacta (squash) as mudanças do featureB ali, resolve qualquer conflito, faz a mudança de implementação, e então publica isto como um novo branch:
$ git checkout -b featureBv2 origin/master
$ git merge --squash featureB
... mudando implementação ...
$ git commit
$ git push meufork featureBv2A opção --squash pega todo o trabalho no branch mesclado e comprime em um novo conjunto gerando um novo estado de repositório como se uma mescla real tivesse acontecido, sem realmente mesclar os commites.
Isto significa que seu commit futuro terá um pai apenas e te permite introduzir todas as mudanças de um outro branch e então aplicar mais alterações antes de gravar seu novo commit.
A opção --no-commit também pode ser útil para atrasar a integração do commit no caso do processo de mesclagem padrão.
Neste ponto, você pode notificar os mantenedores que você já fez as mudanças pedidas, e que eles podem encontrá-las no branch featureBv2.
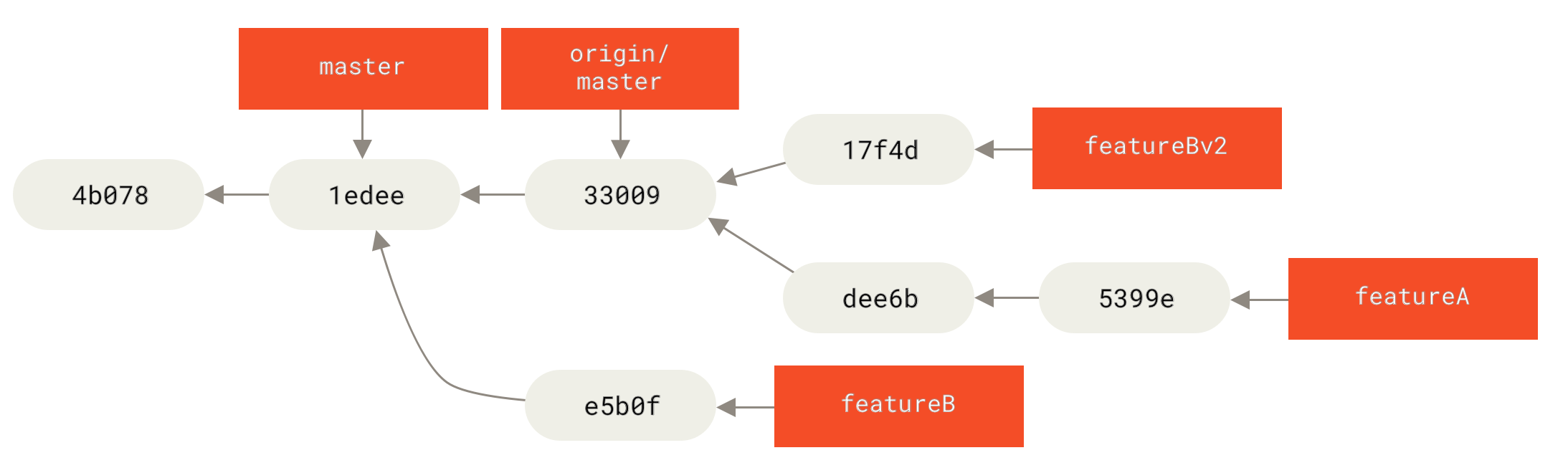
featureBv2
Projeto Público através de Email
Muitos projetos têm procedimentos estabelecidos para aceitar patches — você irá precisar checar as regras específicas para cada projeto, pois elas serão diferentes. Já que existem vários projetos mais antigos, maiores, que aceitam patches através de uma lista de emails de desenvolvedores, iremos exemplificar isto agora:
O fluxo de trabalho é parecido ao caso anterior — você cria branches separados para cada série de patches em que trabalhar. A diferença é como enviá-los ao projeto. Ao invés de fazer um fork do projeto e publicar sua própria versão editável, você gera versões de email de cada série de commites e as envia para a lista de email dos desenvolvedores:
$ git checkout -b assuntoA
... trabalho ...
$ git commit
... trabalho ...
$ git commit
Agora você tem dois commites que gostaria de enviar para a lista de email.
Você pode usar git format-patch para gerar os arquivos formatados em mbox e enviar para a lista de email — isto transforma cada commit em uma mensagem de email, com a primeira linha da mensagem do commit como o assunto, e o resto da mensagem mais o patch que o commit traz como o corpo do email.
O legal disto é que aplicar um patch de email gerado com format-patch preserva todas as informações de commit corretamente.
$ git format-patch -M origin/master
0001-adicionar-limite-para-a-função-log.patch
0002-aumentar-a-saída-do-log-para-30-de-25.patchO comando format-patch exibe os nomes dos arquivos de patch que cria.
A chave -M diz ao Git para procurar por renomeações.
Os arquivos acabam se parecendo com isto:
$ cat 0001-adicionar-limite-para-a-função-log.patch
From 330090432754092d704da8e76ca5c05c198e71a8 Mon Sep 17 00:00:00 2001
From: Jessica Smith <jessica@example.com>
Date: Sun, 6 Apr 2008 10:17:23 -0700
Subject: [PATCH 1/2] Adicionar limite a função log
Limitar a função log aos primeiros 20
---
lib/simplegit.rb | 2 +-
1 files changed, 1 insertions(+), 1 deletions(-)
diff --git a/lib/simplegit.rb b/lib/simplegit.rb
index 76f47bc..f9815f1 100644
--- a/lib/simplegit.rb
+++ b/lib/simplegit.rb
@@ -14,7 +14,7 @@ class SimpleGit
end
def log(treeish = 'master')
- command("git log #{treeish}")
+ command("git log -n 20 #{treeish}")
end
def ls_tree(treeish = 'master')
--
2.1.0Você também pode editar estes arquivos de patch para adicionar mais informação para a lista de email que você não gostaria de colocar na mensagem do commit.
Se você adicionar texto entre a linha --- e o começo do patch (a linha `diff --git), os desenvolvedores podem ler, mas o conteúdo é ignorado pelo processo de patch.
Para enviar este email para uma lista de emails, você pode tanto colar o arquivo no seu programa de email quanto enviar via um programa de linha de comando.
Colar o texto geralmente causa problemas de formatação, especialmente com programas ``inteligentes`` que não preservam novas linhas e espaços em branco corretamente.
Felizmente, o Git fornece uma ferramenta para ajudar você enviar patches formatados adequadamente através de IMAP, o que pode ser mais fácil para você.
Iremos demonstrar como enviar um patch via Gmail, no caso o veículo que conhecemos melhor; você pode ler instruções detalhadas de vários programas de email no final do acima mencionado arquivo Documentation/SubmittingPatches no código fonte do Git.
Primeiro, você deve configurar a seção imap no seu arquivo ~/.gitconfig.
Você pode configurar cada valor separadamente com uma série de comandos git config, ou adicioná-los manualmente, mas no final seu arquivo config deve ficar assim:
[imap]
folder = "[Gmail]/Rascunhos"
host = imaps://imap.gmail.com
user = usuario@gmail.com
pass = YX]8g76G_2^sFbd
port = 993
sslverify = falseSe o seu servidor IMAP não usa SSL, as duas últimas linhas provavelmente não são necessárias, e o valor de host será imap:// ao invés de imaps://.
Quando isto estiver pronto, você poderá usar git imap-send para colocar os seus patches no diretório Rascunhos no servidor IMAP especificado:
$ cat *.patch |git imap-send
Resolving imap.gmail.com... ok
Connecting to [74.125.142.109]:993... ok
Logging in...
sending 2 messages
100% (2/2) doneNeste ponto, você deve poder ir ao seu diretório Rascunhos, mudar o campo Para com a lista de email para qual você está mandando o patch, possivelmente copiando (CC) os mantenedores ou pessoas responsáveis pela seção, e enviar o patch.
Você também pode enviar os patches através de um servidor SMTP.
Como antes, você pode configurar cada valor separadamente com uma série de comandos git config, ou você pode adicioná-los manualmente na seção sendemail no seu arquivo ~/.gitconfig:
[sendemail]
smtpencryption = tls
smtpserver = smtp.gmail.com
smtpuser = usuario@gmail.com
smtpserverport = 587Depois que isto estiver pronto, você pode usar git send-email para enviar os seus patches:
$ git send-email *.patch
0001-adicionar-limite-para-a-função-log.patch
0002-aumentar-a-saída-do-log-para-30-de-25.patch
Who should the emails appear to be from? [Jessica Smith <jessica@example.com>]
Emails will be sent from: Jessica Smith <jessica@example.com>
Who should the emails be sent to? jessica@example.com
Message-ID to be used as In-Reply-To for the first email? yEntão, o Git retorna várias informações de log, para cada patch que você está enviando:
(mbox) Adding cc: Jessica Smith <jessica@example.com> from
\line 'From: Jessica Smith <jessica@example.com>'
OK. Log says:
Sendmail: /usr/sbin/sendmail -i jessica@example.com
From: Jessica Smith <jessica@example.com>
To: jessica@example.com
Subject: [PATCH 1/2] Adicionar limite a função log
Date: Sat, 30 May 2009 13:29:15 -0700
Message-Id: <1243715356-61726-1-git-send-email-jessica@example.com>
X-Mailer: git-send-email 1.6.2.rc1.20.g8c5b.dirty
In-Reply-To: <y>
References: <y>
Result: OK|
Tip
|
Se quiser ajuda para configurar seu sistema de email, mais dicas e truques, e um ambiente controlado para enviar um patch de teste através de email, acesse [git-send-email.io](https://git-send-email.io/). |
Resumo
Nesta seção nós abordamos múltiplos fluxos de trabalho, e falamos sobre as diferenças entre trabalhar como parte de uma equipe pequena em projetos de código fechado, e contribuir para um grande projeto público. Você sabe checar por erros de espaços em branco antes do seu commit, e pode escrever uma excelente mensagem nele. Você aprendeu como formatar patches, e enviá-los por email para a lista de desenvolvedores. Lidando com combinações também foi coberto no contexto de diferentes fluxos de trabalho. Você está agora bem preparado para colaborar com qualquer projeto.
A seguir, você verá como trabalhar no outro lado da moeda: mantendo um projeto Git. Aprenderá como ser um ditador benevolente ou um coordenador.